A Curious Bug in the Commodore BASIC Tokenizer Routine
Investigations into a lesser known bug in Commodore BASIC abbreviations.

Commodore BASIC has a pretty well known, special feature, namely BASIC abbreviations. These are not about the standard “?” for “PRINT”, but another feature common to all Commodore implementations of 8-bit Microsoft BASIC: you may abbreviate any BASIC command by just typing any of the consecutive characters shifted and it will expand to the full keyword (with a bit of luck the right one).
E.g., you may type “P▔” (in lower case character display “pE”) and this will expand to “PEEK”.
This is, because, as soon as you hit RETURN on the keyboard, your input line will be transferred to an internal buffer and tokenized from there. Meaning,a routine will scan over the characters and replace any keywords found by a single-byte token. This doesn’t only help saving memory but also speeds up the interpretation of the program in runtime considerably.
Now YouTuber “8-Bit Show And Tell” has made a nice video on this (www.youtube.com/watch?v=AYhuPM0KH1o) and presented a rather curious bug in this routine. Doing so, he also encouraged comments on what may be causing this bug. — Which is why you are now reading this blog post.
The Bug
So what happens, if we try abbreviating a keyword by the very last character, say, as in “gosuB”?
(I'm further referring to these BASIC keywords in lower case for readability.)
Let’s give it a try, here on the PET 2001 with ROM 2.0, which features — much to our comfort — a hex monitor already built into ROM:
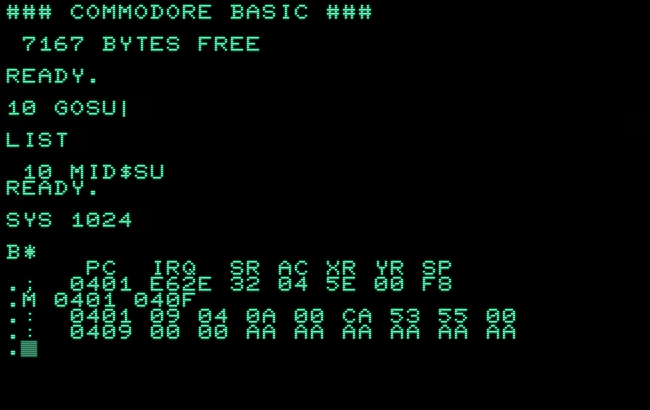
What the fun is happening here? This is really a bit embarrassing!
We may have expected any kind of failure, but why is “mid$” showing up here?
0401: 09 04 0A 00 CA 53 55 00 ....⌷SU. 0409: 00 00 ..
As we inspect the line of BASIC resulting from this portion in RAM (starting on the PET at $0401), we can see what has actually become of our input: the first two bytes ($09 and $04) provide the address of the next line ($0409), the next two bytes ($0A and $00) hold the number of our line (10), which consists of $CA, the token for “mid$” (74 + 128), followed by $53 and $55, the PETSCII codes for “S” and “U”. No sign of the “B” as the line closes with a trailing zero-byte ($00).
(The two zero-bytes for the address of the next line at $0409 indicate the end of the program.)
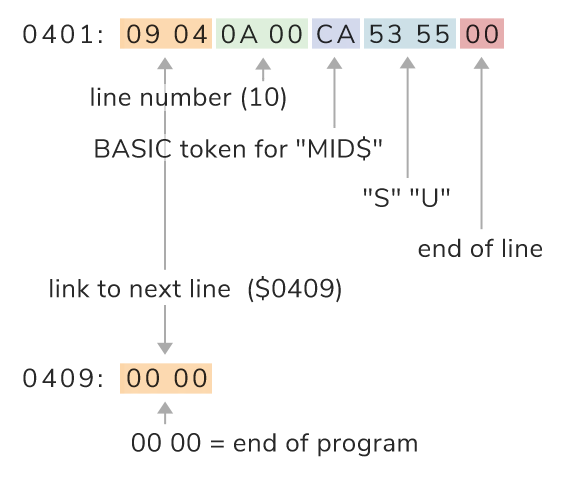
Note: This is essentially the same for other 8-bit Commodore machines, like the C64, where BASIC memory starts at address $0801.
Similar happens with “gotO”, but no other abbreviated token in the entire list of keywords:
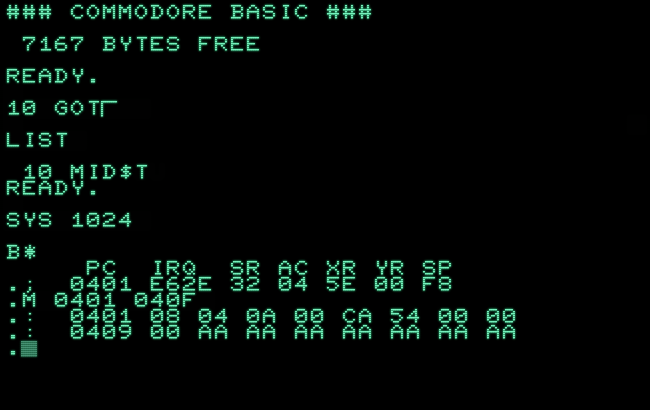
As it happens, Commodore BASIC has a not so well known keyword “GO” (to be used together with the keyword “, which is normally used in a TO”FOR-loop) to form a two-words alternative for “GOTO”. For some reason, the tokenizing routine fails to match this one correctly and uses the token for “MID$” instead. As we’ll see, this is the token immediately preceeding “GO” in the keyword list in ROM. For some reason, the matching routine falls short by 1 — and this only happens with “GO” in “GOSUB” and “GOTO” with the last character shifted.
The very first version of Commodore BASIC, ROM 1.0 for the PET 2001, didn't have the “GO” keyword. Let’s see what’s happening there:
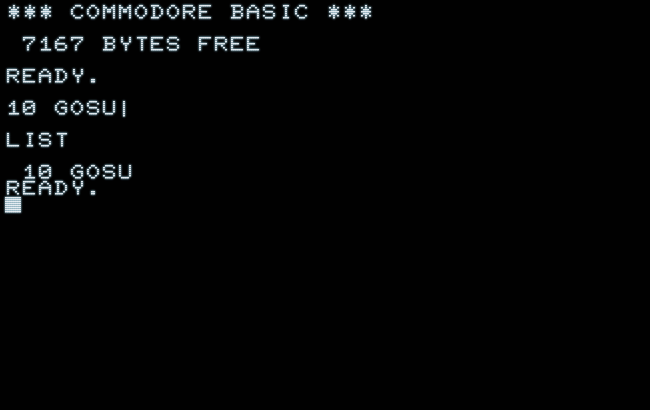
This is consitent with the behavior with any other abbreviations on the last character. It is also consistent with any shifted characters, like the very last one, normally being lost in translation tokenization. (This is, because tokens are discerned by any other bytes in BASIC memory by having their sign-bit set, which is exclusive to them. So any other upper-case characters have to go and are dropped, if not inside a string or comment.) If we risk a peek into RAM (still with ROM 1.0), we see that nothing has been tokenized at all and there are just the bare PETSCII codes for “GOSU” with the upper-case “B” entirely ignored:
0401: 0A 04 0A 00 47 4F 53 55 ....GOSU 0409: 00 00 00 ...
This seems to confirm that this somehow specially related to the “GO” keyword and its token. But how?
Tokenizing
Let’s have a look at the ROM, here the C64 ROM.
The first thing, we need, is a table of the keywords to match — and this is found at address $A09E:
45 4E C4 ;enD ( 0) 46 4F D2 ;foR ( 1) 4E 45 58 D4 ;nexT ( 2) 44 41 54 C1 ;datA ( 3) 49 4E 50 55 54 A3 ;input# ( 4) 49 4E 50 55 D4 ;inpuT ( 5) 44 49 CD ;diM ( 6) 52 45 41 C4 ;reaD ( 7) 4C 45 D4 ;leT ( 8) 47 4F 54 CF ;gotO ( 9) 52 55 CE ;ruN (10) 49 C6 ;iF (11) 52 45 53 54 4F 52 C5 ;restorE (12) 47 4F 53 55 C2 ;gosuB (13) 52 45 54 55 52 CE ;returN (14) 52 45 CD ;reM (15) 53 54 4F D0 ;stoP (16) 4F CE ;oN (17) 57 41 49 D4 ;waiT (18) 4C 4F 41 C4 ;loaD (19) 53 41 56 C5 ;savE (20) 56 45 52 49 46 D9 ;verifY (21) 44 45 C6 ;deF (22) 50 4F 4B C5 ;pokE (23) 50 52 49 4E 54 A3 ;print# (24) 50 52 49 4E D4 ;prinT (25) 43 4F 4E D4 ;conT (26) 4C 49 53 D4 ;lisT (27) 43 4C D2 ;clR (28) 43 4D C4 ;cmD (29) 53 59 D3 ;syS (30) 4F 50 45 CE ;opeN (31) 43 4C 4F 53 C5 ;closE (32) 47 45 D4 ;geT (33) 4E 45 D7 ;neW (34) 54 41 42 A8 ;tab( (35) 54 CF ;tO (36) 46 CE ;fN (37) 53 50 43 A8 ;spc( (38) 54 48 45 CE ;theN (39) 4E 4F D4 ;noT (40) 53 54 45 D0 ;steP (41) AB ;+ (42) AD ;- (43) AA ;* (44) AF ;/ (45) DE ;^ (46) 41 4E C4 ;anD (47) 4F D2 ;oN (48) BE ;> (49) BD ;= (50) BC ;< (51) 53 47 CE ;sgN (52) 49 4E D4 ;inT (53) 41 42 D3 ;abS (54) 55 53 D2 ;usR (55) 46 52 C5 ;frE (56) 50 4F D3 ;poS (57) 53 51 D2 ;sqR (58) 52 4E C4 ;rnD (59) 4C 4F C7 ;loG (60) 45 58 D0 ;exP (61) 43 4F D3 ;coS (62) 53 49 CE ;siN (63) 54 41 CE ;taN (64) 41 54 CE ;atN (65) 50 45 45 CB ;peeK (66) 4C 45 CE ;leN (67) 53 54 52 A4 ;str$ (68) 56 41 CC ;vaL (69) 41 53 C3 ;asC (70) 43 48 52 A4 ;chr$ (71) 4C 45 46 54 A4 ;left$ (72) 52 49 47 48 54 A4 ;right$ (73) 4D 49 44 A4 ;mid$ (74) 47 CF ;gO (75) 00 ;marker end-of-list
As we may observe, there are 76 tokens (0..75), including all the keywords and arithmetic operators, terminated by a final zero-byte as an end marker. Each keyword has the sign-bit (bit 7) set at its last character to mark the end of this keyword, which also happens to be upper-case in PETSCII.
(The PET 2001 ROM 1.0 is missing the very last keyword, “gO”, but has the exact same list otherwise.)
Now, let’s have a look at how this is actually used.
The tokenizing is done in routine “CRUNCH” at $A57C:
A57C LDX $7A load index into BASIC buffer, low byte
A57E LDY #$04 load value 4
A580 STY $0F and save it in $0F as quote/DATA flag
A582 LDA $0200,X get a byte from the BASIC buffer
A585 BPL $A58E sign-bit set? if not, continue at $A58E
A587 CMP #$FF is it PI?
A589 BEQ $A5C9 yes, jump to $A5C9 and use it as a token as-is
A58B INX increment read index
A58C BNE $A582 loop, this branch is always taken
A58E CMP #$20 compare with SPACE
A590 BEQ $A5C9 if SPACE, jump to $A5C9 and save as-is
A592 STA $08 back up the current input character
A594 CMP #$22 is it a quote character?
A596 BEQ $A5EE yes, jump to $A5EE and copy the string
A598 BIT $0F check open quote/DATA flag
(contents($0F) AND AC, V = bit 6 of result)
A59A BVS $A5C9 continue at $A5C9, if overflow flag set,
and save the last byte
A59C CMP #$3F is it a "?" character
A59E BNE $A5A4 no, continue at $A5A4
A5A0 LDA #$99 use $99, the token of PRINT
A5A2 BNE $A5C9 save it (branches always)
A5A4 CMP #$30 compare with "0"
A5A6 BCC $A5AC continue at $A5AC, if samller
A5A8 CMP #$3C compare with "<"
A5AA BCC $A5C9 continue at $A5AC and save as-is, if smaller
(this catches 0123456789:;)
continue with any other, normal characters:
A5AC STY $71 backup index
A5AE LDY #$00 clear Y, used as pointer into the keyword table
A5B0 STY $0B clear the token index
A5B2 DEY and adjust for pre-increment loop
A5B3 STX $7A backup index into BASIC buffer, low byte,
A5B5 DEX and adjust for pre-increment loop
match the next character:
A5B6 INY increment index of keyword table
A5B7 INX increment index of BASIC buffer
A5B8 LDA $0200,X get byte from BASIC buffer
A5BB SEC set carry for subtraction
A5BC SBC $A09E,Y subtract keyword byte
A5BF BEQ $A5B6 if equal, match the next character
A5C1 CMP #$80 is the difference $80 (end of word)?
A5C3 BNE $A5F5 if not, continue at $A5F5 for the next keyword
save a byte or token:
A5C5 ORA $0B OR it with $80 (in $0B) to make it a token
A5C7 LDY $71 get index for saving
A5C9 INX increment buffer index for reading
A5CA INY increment buffer index for saving
A5CB STA $01FB,Y save it in output buffer
A5CE LDA $01FB,Y read it again to set flags
A5D1 BEQ $A609 if zero [EOL], continue at $A609
A5D3 SEC set carry for subtraction
A5D4 SBC #$3A subtract ":" (seperator)
A5D6 BEQ $A5DC if zero (we have a match), continue at $A5DC
AC is now token − ":"
A5D8 CMP #$49 compare with the token for DATA − ":"
A5DA BNE $A5DE no match, branch to $A5DE to compare for REM
token was ":" or DATA
(meaning, we either close or open a data statement.)
A5DC STA $0F save the token − $3A as flag in $0F
(this is checked above by the BIT instruction)
A5DE SEC set carry for subtraction
A5DF SBC #$55 subtract the token for REM − ":"
A5E1 BNE $A582 if no match, continue at $A582 to match the next character
A5E3 STA $08 REM, search for EOL, save AC (0) in $08
A5E5 LDA $0200,X get byte from input buffer
A5E8 BEQ $A5C9 if zero EOL save jump to $A5C9 and save it as-is
A5EA CMP $08 compare with stored character (might be quote)
A5EC BEQ $A5C9 if it matches, jump to $A5C9 to continue normally
A5EE INY increment the save index
A5EF STA $01FB,Y and copy the byte to the output buffer
A5F2 INX increment the buffer index
A5F3 BNE $A5E5 check for run-over (line too long)
prepare for next keyword:
A5F5 LDX $7A restore BASIC buffer index, low byte
A5F7 INC $0B increment token index (next keyword)
find the end of the current keyword:
A5F9 INY increment table index
A5FA LDA $A09D,Y and read the byte
A5FD BPL $A5F9 if sign-bit not set, redo
A5FF LDA $A09E,Y read the first byte from the new keyword
A602 BNE $A5B8 if not zero, branch to $A5B8 and try a match
We reached the zero-byte marking the endo of the keyword table
A604 LDA $0200,X restore byte from input buffer
A607 BPL $A5C7 if sign-bit not set, branch to $A5C7 to save as is and continue
handle EOL:
A609 STA $01FD,Y save it (EOL)
A60C DEC $7B decrement BASIC buffer pointer, high byte
A60E LDA #$FF point to start of buffer − 1
A610 STA $7A set BASIC buffer pointer low byte
A612 RTS return
The interesting part of this is the keyword matching routine at the very center of this piece of 6502 assembler code. Let’s rewrite this in JavaScript:
var characterIndex = 0; // current character in 'lineBuffer'
var keywordIndex; // current keyword byte in array 'keywords'
var keywordCount; // token/keyword count
var startIndex; // backup for back-tracking
outer: while(true) {
// here, we skip the handling of any bytes >= 0x80 (Pi)
// and of quotes and data statements.
// as we continue, we're sure we're in the range 0 >= byte < 0x80.
// reset indices for keyword matching
keywordCount = 0;
keywordIndex = 0;
// prepare for the pre-increment loop
characterIndex--;
keywordIndex--;
// and keep track of were we started from
startIndex = characterIndex;
inner: while(true) {
characterIndex++;
keywordIndex++;
var c = lineBuffer[characterIndex];
var delta = c - keywords[keywordIndex];
if (delta == 0) {
continue inner; // same, continue matching
}
else if (delta == 0x80) {
// actually (Math.abs(delta) == 0x80)
// found end of keyword or word while matching
outputBuffer.push( keywordCount | 0x80 );
// (if REM, copy any characters until EOL;
// if DATA, set flag;)
// continue matching on next input character
characterIndex++;
continue outer;
}
else {
// non-matching characters, try the next keyword
// reset the input-pointer and increment the keyword-count
characterIndex = startIndex;
keywordCount++;
// consume any remaining bytes in last keyword
while (keywords[++keywordIndex] && 0x80 == 0);
if (keywords[keywordIndex + 1] == 0) {
// we reached the end of the keyword table
if (c > 0 && c < 0x80) {
// we were looking at a normal character, save as-is
outputBuffer.push( c );
// continue matching on next input character
characterIndex++;
continue outer;
}
else {
// must be zero => EOL
outputBuffer.push( c );
// (adjust pointers to output buffer)
// and exit the loop
break outer;
}
}
}
}
}
So what’s happening here? As we enter the loop, the two pointers into the line-buffer and the keyword table are prepared for a pre-increment loop, and now we're going to match the bytes in pairs. In oder to do so, we get the difference (delta) of the two bytes. If the difference is zero, we have a perfect match and try, if the next character might match as well.
However, if the difference is $80, we also have a match, but, moreover, we have reached the end of the keyword, we're currently comparing. Notably, in 8-bits negative $80 is the same as positive $80, so we're actually comparing the absolute offset and it doesn’t matter, which of the two operands is greater and which one is smaller. The difference of the two operands is just the sign-bit (bit 7), regardless, which of the two bytes has it set. This is also, where Commodore BASIC abbreviations come from, as this works both ways: As we were matching a keyword, this produces a premature match, if the word in the input-buffer has the sign-bit set, and we get the token of the first keyword in the table which starts with this string. Anyway, if we do have a match, the count of the keyword + $80 (again, the sign-bit set) will be used as the token and stored in the output buffer.
Otherwise, if there is no match (indicated by a delta other than zero or $80), we continue with the next keyword. For this, we restore the input-pointer (characterIndex) to a stored starting value (since we may have had a partial match previously) and increment the keyword count. Then, we have to skip any remaining bytes of the previous keyword, reading ahead any number bytes from the keyword table until we hit one with the sign-bit set, indicating the end of that keyword. If the next byte in the keyword table is zero, we have reached the end marker byte and store the first character as-is. Now, we've to check, if there are any bytes left in the input-buffer. If so, we continue the loop and attempt to match the new keyword.
The gosuB-Bug
Now we may already see, what’s happening, as we try to match “gosuB”. The algorithm happily matches the first 4 characters of the keyword “gosuB” (keyword #13), but it fails to discern the end of either word, since the two upper-case Bs are a perfect match, as well. So the code spills over into the next keyword (also causing a buffer overflow in the input-buffer), now trying to also match the characters of the next keyword, “returN”. However, the keyword count still holds 13, now lagging behind by 1. As this match fails, the keyword count is finally incremented, but is still lagging behind by one. And, as we finally have a match on “gO”, the degraded keyword count is used for the token, falling short by 1, which is actually “MID$” and not “GO”. The two remaining lower-case characters are then used as-is, and the final upper-case “B” ignored, resulting in the infamous “MID$SU”.
The same also applies to “gotO”, where the keyword count fails on “RUN”, still using 9 (“GOTO”) instead of 10. This will generally apply to any condition, where a later keyword is a substring of a longer, previous one, as ordered in the keyword table. However, there are no other combinations than the ones with “GO”.
Or are there?
What about “INPUT#” and “INPUT”, following immediately one another? What, if we try the character matching “#” with the sign-bit set as the last one? (PETSCII #163, on the C64 this is C=+T.)
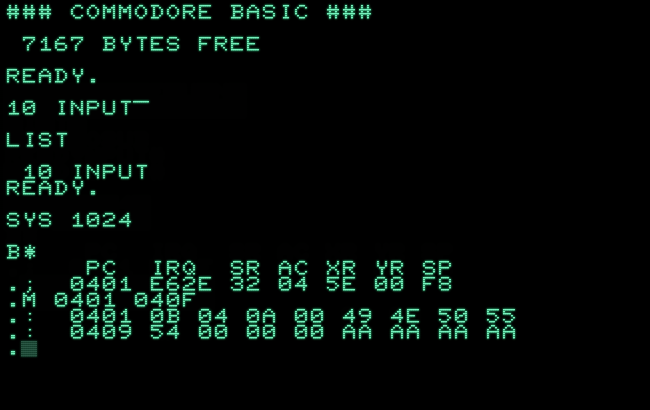
While this may look like a BASIC command, it isn’t. Having a closer look at the tokenized code in RAM, we see that there's nothing tokenized at all, just the bare PETSCII values:
0401: 0B 04 0A 00 49 4E 50 55 ....INPU 0409: 54 00 00 00 T...
As the algorithm is trying to match the concatenated keywords “input▔inpuT”, it fails on the second “i” and returns, in absence of another match, just the bare lower-case characters (omitting the upper-case “#”.)
So, what happens, if we supply an “appropriate” input-string?
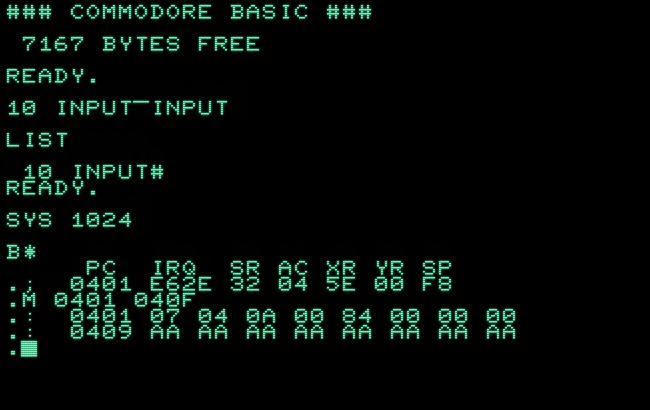
Now, the tokenizer recognizes our combined monster keyword “input▔input” and returns the token for the first part, “INPUT#” or $84!
Can we do similarly with “gosuB”?
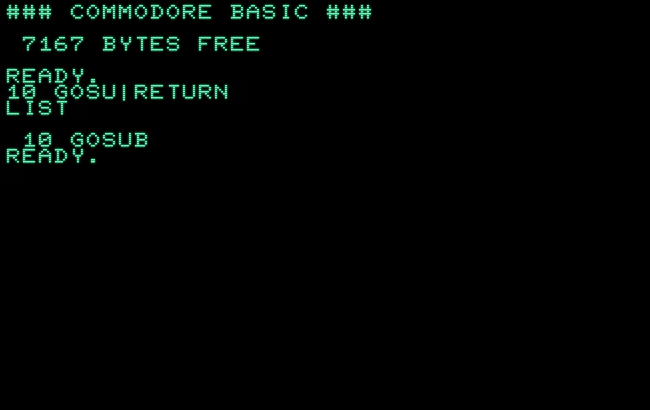
Yes, we can! As the algorithm finally triggers on the last character of “RETURN”, the keyword following immediately after “GOSUB”, it actually returns the token for “GOSUB”!
Somewhat embarrassing, but a token, at least… :-)
Norbert Landsteiner,
Vienna, 2019-05-10