The REM-arkable Misadventures of LIST
A proper account of the deplorable life and times of the LIST routine in Commodore BASIC.
As witnessed by the author and here brought forward as a Cautionary Tale and Moral Entertainment to the Educated & Erudite Reader, in Due Gratefulness for the unflagging & sturdy & untiring Efforts as demonstrated by the Hosting Company committed to the proper & timely distribution of this humble Website and the variety of bits & bytes thereof.

In our last installment we had a closer look into the tokenizer routine (also known as CRUNCH) in Commodore BASIC. This time, we follow up on this by a closer look into the reverse operation, namely the “LIST” command, which — among other things — has to expand the various BASIC tokens into human readable keywords back again. What could possibly go wrong?
A Graphic Story of Failings
Content warning: the following section may contain disturbing images. ;-)
Previously, we observed that the tokenizer routine parses the payload of a REM statement like a string that extends to the very end of the line, copying any characters, there are, to the BASIC program text as-is. And we remarked that this was not how the LIST routines handles such remarks.
Let’s have fun with an example and see what happens, and what might go wrong:
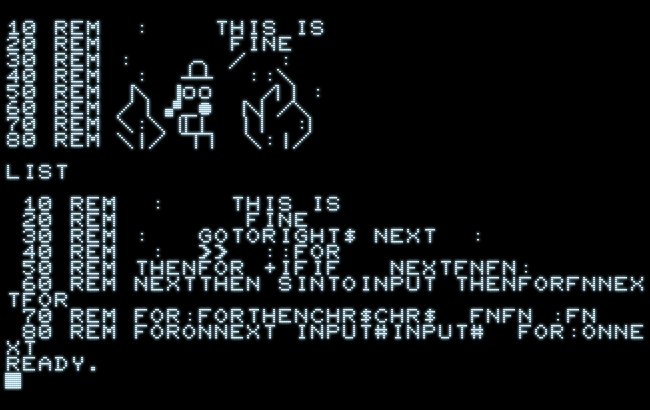
Well, this came unexpected!
It should be quite clear what has happened here:
Instead of just printing the characters in the REM statement as-is, reproducing them as the unquoted string, they had been parsed as, the LIST routine continues to expand any bytes with a set sign-bit — meaning, any shifted PETSCII characters — to BASIC keywords, in order to please its human masters by the presentation of readable text. The human masters are not pleased, though.
Even worse, the LIST routine may even fail entirely over this operation, aborting with an error:
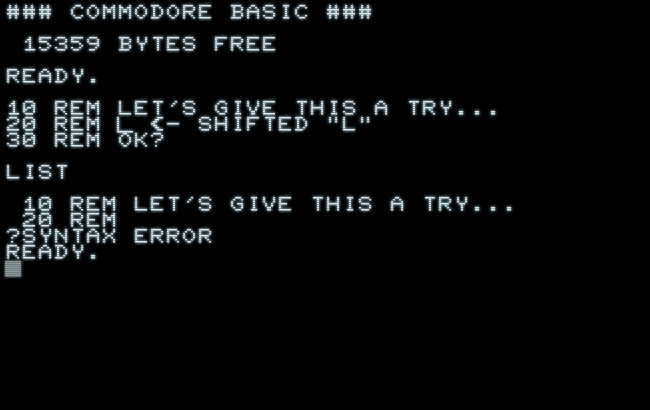
Peculiarly, the listing fails over a shifted “L” character, just to report a “SYNTAX ERROR”, where there is no syntax to check, at all!
As the versed enthusiast may know already, SHIFT-L is PETSCII code 0xCC. Let‘s see, what may happen with adjacent characters (here in lower-case/upper-case mode):
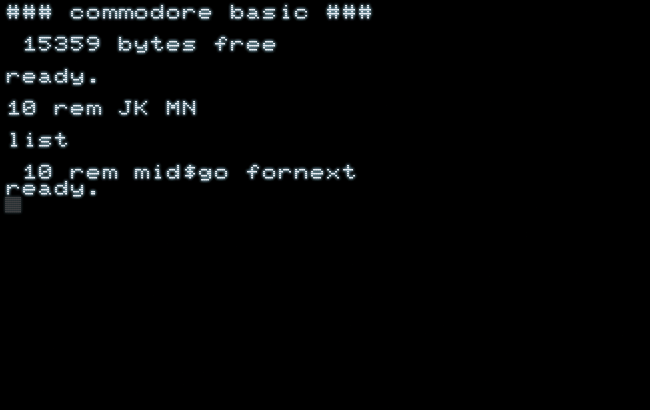
That‘s interesting: LIST doesn‘t fail over anything beyond 0xCC.
There may be a system to this. Let’s compare our finding to what we know about BASIC tokens:
| input | graphics | petscii | keyword | token |
|---|---|---|---|---|
| SHIFT-J | ╰ |
0xCA |
MID$ |
0xCA |
| SHIFT-K | ╰ |
0xCB |
GO |
0xCB |
| SHIFT-L | ᒪ |
0xCC |
error | %0 |
| SHIFT-M | ╲ |
0xCD |
FOR |
0x81 |
| SHIFT-N | ╱ |
0xCE |
NEXT |
0x82 |
It seems, input characters and tokens do correspond: 0xCC corresponds to the zero-byte, which terminates the keyword list, and beyond this, it wraps around! — Indeed, in our introductory experiment, there were plenty of SHIFT-Ms (╲) and SHIFT-Ns (╱), and these were listed as FOR and NEXT, respectively.
To recapitulate, here’s the keyword-token table from our tokenizing episode (underlined characters indicate a set sign-bit):
code keyword token index 45 4E C4 END 0x80 ( 0) 46 4F D2 FOR 0x81 ( 1) 4E 45 58 D4 NEXT 0x82 ( 2) 44 41 54 C1 DATA 0x83 ( 3) 49 4E 50 55 54 A3 INPUT# 0x84 ( 4) 49 4E 50 55 D4 INPUT 0x85 ( 5) 44 49 CD DIM 0x86 ( 6) 52 45 41 C4 READ 0x87 ( 7) 4C 45 D4 LET 0x88 ( 8) 47 4F 54 CF GOTO 0x89 ( 9) 52 55 CE RUN 0x8A (10) 49 C6 IF 0x8B (11) 52 45 53 54 4F 52 C5 RESTORE 0x8C (12) 47 4F 53 55 C2 GOSUB 0x8D (13) 52 45 54 55 52 CE RETURN 0x8E (14) 52 45 CD REM 0x8F (15) 53 54 4F D0 STOP 0x90 (16) 4F CE ON 0x91 (17) 57 41 49 D4 WAIT 0x92 (18) 4C 4F 41 C4 LOAD 0x93 (19) 53 41 56 C5 SAVE 0x94 (20) 56 45 52 49 46 D9 VERIFY 0x95 (21) 44 45 C6 DEF 0x96 (22) 50 4F 4B C5 POKE 0x97 (23) 50 52 49 4E 54 A3 PRINT# 0x98 (24) 50 52 49 4E D4 PRINT 0x99 (25) 43 4F 4E D4 CONT 0x9A (26) 4C 49 53 D4 LIST 0x9B (27) 43 4C D2 CLR 0x9C (28) 43 4D C4 CMD 0x9D (29) 53 59 D3 SYS 0x9E (30) 4F 50 45 CE OPEN 0x9F (31) 43 4C 4F 53 C5 CLOSE 0xA0 (32) 47 45 D4 GET 0xA1 (33) 4E 45 D7 NEW 0xA2 (34) 54 41 42 A8 TAB( 0xA3 (35) 54 CF TO 0xA4 (36) 46 CE FN 0xA5 (37) 53 50 43 A8 SPC( 0xA6 (38) 54 48 45 CE THEN 0xA7 (39) 4E 4F D4 NOT 0xA8 (40) 53 54 45 D0 STEP 0xA9 (41) AB + 0xAA (42) AD - 0xAB (43) AA * 0xAC (44) AF / 0xAD (45) DE ^ 0xAE (46) 41 4E C4 AND 0xAF (47) 4F D2 ON 0xB0 (48) BE > 0xB1 (49) BD = 0xB2 (50) BC < 0xB3 (51) 53 47 CE SGN 0xB4 (52) 49 4E D4 INT 0xB5 (53) 41 42 D3 ABS 0xB6 (54) 55 53 D2 USR 0xB7 (55) 46 52 C5 FRE 0xB8 (56) 50 4F D3 POS 0xB9 (57) 53 51 D2 SQR 0xBA (58) 52 4E C4 RND 0xBB (59) 4C 4F C7 LOG 0xBC (60) 45 58 D0 EXP 0xBD (61) 43 4F D3 COS 0xBE (62) 53 49 CE SIN 0xBF (63) 54 41 CE TAN 0xC0 (64) 41 54 CE ATN 0xC1 (65) 50 45 45 CB PEEK 0xC2 (66) 4C 45 CE LEN 0xC3 (67) 53 54 52 A4 STR$ 0xC4 (68) 56 41 CC VAL 0xC5 (69) 41 53 C3 ASC 0xC6 (70) 43 48 52 A4 CHR$ 0xC7 (71) 4C 45 46 54 A4 LEFT$ 0xC8 (72) 52 49 47 48 54 A4 RIGHT$ 0xC9 (73) 4D 49 44 A4 MID$ 0xCA (74) 47 CF GO 0xCB (75) — BASIC 2.0 and later only — 00 <end-of-list>
Let’s verify:
### commodore basic ### 15359 bytes free ready. 10 rem fun with COMMODORE! list 10 rem fun with lendataforfordatastr$da tadimval! ready. █
Where,
SHIFT-C … CHR$(195) … 0xC3 (-0x80: 67) … `LEN` SHIFT-O … CHR$(207) … 0xCF (-0x80: 79 - 76 = 3) … `DATA` SHIFT-M … CHR$(205) … 0xCD (-0x80: 77 - 76 = 1) … `FOR` SHIFT-M … CHR$(205) … 0xCD (-0x80: 77 - 76 = 1) … `FOR` SHIFT-O … CHR$(207) … 0xCF (-0x80: 79 - 76 = 3) … `DATA` SHIFT-D … CHR$(196) … 0xC4 (-0x80: 68) … `STR$` SHIFT-O … CHR$(207) … 0xCF (-0x80: 79 - 76 = 3) … `DATA` SHIFT-R … CHR$(210) … 0xD2 (-0x80: 82 - 76 = 6) … `DIM` SHIFT-E … CHR$(197) … 0xC5 (-0x80: 69) … `VAL`
— ✓ checks! —
So, let’s have a look into how LENDATAFORFORDATASTR$DATADIMVAL BASIC achieves this.
The LIST Routine
Once again, we use the “New ROM” version as common ground, since it represents a consolidated, bug-fixed version that also served as the basis for the BASIC V.2 of the VIC-20 and C64. Here, the LIST routine is found at $C5B5:
;BASIC command `LIST`
C5B5 BCC iC5BD ;parse arguments and set up range
C5B7 BEQ iC5BD
C5B9 CMP #$AB
C5BB BNE $C5A6
C5BD iC5BD JSR $C873
C5C0 JSR $C52C
C5C3 JSR $0076
C5C6 BEQ iC5D4
C5C8 CMP #$AB
C5CA BNE $C55A
C5CC JSR $0070
C5CF JSR $C873
C5D2 BNE $C55A
C5D4 iC5D4 PLA
C5D5 PLA
C5D6 LDA $11
C5D8 ORA $12
C5DA BNE iC5E2
C5DC LDA #$FF
C5DE STA $11
C5E0 STA $12
C5E2 iC5E2 LDY #$01 ;list a line; reset cursor
C5E4 STY $09 ;and reset mode flag to zero
C5E6 LDA ($5C),Y ;load link address high-byte
C5E8 BEQ iC62D ;it's zero! finish…
C5EA JSR $FFE1 ;test for STOP key pressed
C5ED JSR $C9E2 ;output Carrige Return (CR) for a new line
C5F0 INY ;advance cursor
C5F1 LDA ($5C),Y ;load line number low-byte
C5F3 TAX ;into X
C5F4 INY ;advance cursor
C5F5 LDA ($5C),Y ;load line number high-byte
C5F7 CMP $12 ;is it the end of range?
C5F9 BNE iC5FF ;no: skip next…
C5FB CPX $11 ;compare low-byte to end of range
C5FD BEQ iC601 ;same: skip to list the line…
C5FF iC5FF BCS iC62D ;it's greater: finish…
C601 iC601 STY $46 ;store cursor
C603 JSR $DCD9 ;output line number (in X and A)
C606 LDA #$20 ;load code for blank
C608 iC608 LDY $46 ;list a program byte; first, (re)load cursor
C60A AND #$7F ;clear sign-bit
C60C iC60C JSR $CA45 ;output character (acc. restored on return)
C60F CMP #$22 ;is it a quotation mark (`"`)?
C611 BNE iC619 ;no: skip next…
C613 LDA $09 ;reverse mode flag; load it
C615 EOR #$FF ;flip bits
C617 STA $09 ;store it
C619 iC619 INY ;advance cursor
C61A BEQ iC62D ;overflow (line too long), abort/finish…
C61C LDA ($5C),Y ;read next char
C61E BNE iC630 ;UN-CRUNCH, unless end of line
C620 TAY ;line termination; zero into Y
C621 LDA ($5C),Y ;read from beginning of the (link low-byte)
C623 TAX ;into X
C624 INY ;advance cursor
C625 LDA ($5C),Y ;read next byte (link high-byte)
C627 STX $5C ;store it as new base pointer (low-byte)
C629 STA $5D ;store it (high-byte)
C62B BNE iC5E2 ;process line, unless high-byte is zero (EOT)
C62D iC62D JMP $C389 ;finish! jump to BASIC warm start for reset
;UN-CRUNCH
C630 iC630 BPL iC60C ;not a token, branch to print it…
C632 CMP #$FF ;is it pi (`π`)?
C634 BEQ iC60C ;yes, branch to output…
C636 BIT $09 ;check mode flag for quoted string
C638 BMI iC60C ;if set, branch to output as-is and redo…
C63A SEC ;it's a token: prepare subtraction
C63B SBC #$7F ;subtract 0x80 - 1 (clear sign-bit, add 1)
C63D TAX ;as a keyword counter into X
C63E STY $46 ;store cursor
C640 LDY #$FF ;prepare for pre-increment loop
C642 iC642 DEX ;decrement keyword counter
C643 BEQ iC64D ;if zero: found keyword, print it…
C645 iC645 INY ;increment read cursor
C646 LDA $C092,Y ;load next byte
C649 BPL iC645 ;redo for next byte, if not last char…
C64B BMI iC642 ;branch to count-down on next keyword… (unconditional)
C64D iC64D INY ;print keyword; advance cursor
C64E LDA $C092,Y ;load next character
C651 BMI iC608 ;if end of keyword, redo for next char in line…
C653 JSR $CA45 ;output the character (acc. restored on return)
C656 BNE iC64D ;redo for next keyword char (unconditional)
Let’s have a little walk-trough. We‘re not so much interested in the first two sections. The former reads any and parses any arguments to set up the range of the listing. The latter is mildly interesting in our context: this is were we start to list a line, by first reading and checking the high-byte of the linkt to the next line of BASIC, we check for the end of program, and then proceed to read and check the line number (if the current line number is greater than the end of the range, we really ought to finish).
With setup and checks done, we print the line number in a new line and are ready to process the payload. As we approach our first block of interest at $C608, the Y register holds a cursor (index) into the current line for the read position and the accumulator holds the code for a blank character, we’re going to print next.
C608 A4 46 iC608 LDY $46 ;restore cursor from backup C60A 29 7F AND #$7F ;clear sign-bit in byte to print C60C 20 45 CA iC60C JSR $CA45 ;print character C60F C9 22 CMP #$22 ;`"`? C611 D0 06 BNE iC619 ;no… C613 A5 09 LDA $09 ;load mode flag C615 49 FF EOR #$FF ;flip bits C617 85 09 STA $09 ;store it C619 C8 iC619 INY ;advance cursor C61A F0 11 BEQ iC62D ;branch on overflow C61C B1 5C LDA ($5C),Y ;read next char C61E D0 10 BNE iC630 ;branch to handle it, unless zero (EOL)
This is the major character processing loop, beginning with the output of the current character. First, we restore the cursor into the line of BASIC, then we clear the sign-bit of the byte to handle. This being now a plain and unshifted ASCII character, we jump to a subroutine to print this to the current output channel. (As we enter this on the beginning of a line, this prints the blank, we had loaded previously, separating the line number from the text to follow.)
As this subroutine (or rather, a series of subroutines and jumps) preserves the contents of the accumulator, we can check this caracter immediately for a quotation mark ("). If it is one, we flip a mode flag (in $09). At the next instruction (at $C619), the paths converge again: we advance the cursor (in Y, aborting the routine on the event of an overflow) and read the next byte. If it’s not a zero-byte, indicating the end of the line, we branch forwards to the UN-CRUNCH routineat $C630 to handle it.
C620 A8 TAY ;reset Y C621 B1 5C LDA ($5C),Y ;read link to next line C623 AA TAX ;low-byte into X C624 C8 INY ;advance cursor C625 B1 5C LDA ($5C),Y ;read high-byte C627 86 5C STX $5C ;store it as new base pointer (low-byte) C629 85 5D STA $5D ; -"- (high-byte) C62B D0 B5 BNE iC5E2 ;redo, unless high-byte is zero C62D 4C 89 C3 iC62D JMP iC389 ;end of program, forward to BASIC warm start
If we did just reach the end of the line, we set up for the next one: by transferring the zero value in A into Y, we reset the read cursor to the very beginning of the line in memory. The first two bytes must be the link address to the next line, low-byte and high-byte, and we read them into X and A, respectively, incrementing $5C and $5D).
If the high addresss byte is not zero, we loop back to the code for a new BASIC line, at $C5E2.
This is also anpther check for the end of program: if the high-byte of the link is zero and we fall through, this can’t be a legitimate line address in user memory, it must be the end-of-program marker. Thus, we have finished and jump to the exit of the routine (and from there to the BASIC warm start to reset for the next command).
UN-CRUNCH
Welcome to the main attraction: this is the reverse of the tokenizing routine, for this also known as UN-CRUNCH. This is, where we handle a character for output and expand any tokens to BASIC keywords.
C630 10 DA iC630 BPL iC60C ;not a token, print it… C632 C9 FF CMP #$FF ;`π`? C634 F0 D6 BEQ iC60C ;yes, print it and redo next… C636 24 09 BIT $09 ;check mode flag: in quoted string? C638 30 D2 BMI iC60C ;yes: print and redo next… C63A 38 SEC ;it's a token C63B E9 7F SBC #$7F ;subtract 0x80 - 1 (clear sign-bit, add 1) C63D AA TAX ;use as a keyword counter C63E 84 46 STY $46 ;store cursor C640 A0 FF LDY #$FF ;prepare for pre-increment loop C642 CA iC642 DEX ;decrement counter C643 F0 08 BEQ iC64D ;count-down complete: print keyword… C645 C8 iC645 INY ;increment read cursor C646 B9 92 C0 LDA $C092,Y ;load next byte C649 10 FA BPL iC645 ;redo, if not last char… C64B 30 F5 BMI iC642 ;redo for next keyword… (unconditional) C64D C8 iC64D INY ;advance cursor C64E B9 92 C0 LDA $C092,Y ;load next character C651 30 B5 BMI iC608 ;redo main character loop… C653 20 45 CA JSR $CA45 ;output the character C656 D0 F5 BNE iC64D ;redo for next keyword char (unconditional)
As we enter, the character in question is in the accumulator. If the sign-bit is not set, it’s easy: it’s a plain character and we skip forward to print it. Otherwise, there’s a check for the special case of pi (π) and another one for this being in the middle of a quoted string. In both cases, we may skip forward to output the character as-is.
Otherwise, if we arrived at $C63A, it must be a token and we’re going to expand it into a keyword.
First, we derive an index into the keword list from the token value by subtracting the sign-bit plus one (because it will be a pre-increment loop), amounting to 0x7F. The resulting value will be used for a count-down in X. (E.g., if the token was 0x82 for NEXT, it’s now 3 — and NEXT is actually the 3rd entry in the keyword list, at the zero-based index #2.) The basic idea is that we will skip over n keywords, where n is the keyword index.
But, for a start, we have to store our read cursor for later use and set up the index (in Y) for reading from the list. Because this is a pre-increment loop, we preset it to 0xFF (-1), so that it will be zero for the first iteration.
Next follows the main search-skip loop: we decrement our counter, and, if we reached zero, we’re done and our read index points to just before the proper keyword. Hence, we forward to the end of the search loop to output the given keyword. (As we enter this, this will only be true for END, where the subtraction and pre-increment result in zero, END’s very token.)
Else, if we hadn’t just read what was the last character of a word, as indicated by an unset sign-bit, we read the next character in a tight loop. If the sign-bit is set, on the other hand, it was the last character and we just skipped over an entire keyword, for which we branch to the decrement of the keyword counter for another iteration of the search-skip loop. Notably, this is an unconditional branch: if it is not a negative value, it must be a positive one.
The final part at 0xC64D is actually printing the keyword:
Our index in Y points to the last character of the keyword, just before the one, we’re meaning to print. Thus, we advance the index and read a character from the list. If it has the sign-bit set, it’s the last one and we jump to the entrance of the main character loop, where we will print it and handle any rest of the line. (Now we also know why this should have cleared the sign-bit first before printing.)
Otherwise, we print it to the current output channel by the subroutine at $CA45. This subroutine (we’ve seen it before) preserves the contents of the accumulator, as well as flags, which allows us an elegant and ROM efficient branch to the next iteration of the main character loop. — Notably, this is meant to be an unconditional branch: we just printed a character from our keyword list, and we do know our keyword list, it’s all unshifted and shifted characters. So, a BNE instruction should work fine!
LIST’s Fall & Demise
Alas, Dearest Reader, lament the state of this corruption: there is no provision to catch and handle REM, at all. For a proper inverse of the CRUNCH routine, this would have required *some* check for the respective token (0x8F). Say, just after the check for the quotation mark (`"`) at $C60F and maybe a branch to a tight read-output loop till the next zero-byte. — But, no, there’s no such thing and we’re left with no options, but shedding tears to profess our humanity (apparently a requirement for any self-respecting character in a classic Gothic novel.)
But, honestly, the rest doesn’t look too bad. Yes, tokens will be expanded in any case, but it may not be that obvious how this fails so utterly over graphics characters in remarks. For this, we have to have another look at the keyword list and how this works in conjunction with the count-down in X.
For BASIC 2.0, this starts at $C092 and spans to $C190 (underlined characters indicate a set sign-bit):
addr code petscii C092 45 4E C4 46 4F D2 ENDFOR C098 4E 45 58 D4 44 41 54 C1 NEXTDATA C0A0 49 4E 50 55 54 A3 49 4E INPUT#IN C0A8 50 55 D4 44 49 CD 52 45 PUTDIMRE C0B0 41 C4 4C 45 D4 47 4F 54 ADLETGOT C0B8 CF 52 55 CE 49 C6 52 45 ORUNIFRE C0C0 53 54 4F 52 C5 47 4F 53 STOREGOS C0C8 55 C2 52 45 54 55 52 CE UBRETURN C0D0 52 45 CD 53 54 4F D0 4F REMSTOPO C0D8 CE 57 41 49 D4 4C 4F 41 NWAITLOA C0E0 C4 53 41 56 C5 56 45 52 DSAVEVER C0E8 49 46 D9 44 45 C6 50 4F IFYDEFPO C0F0 4B C5 50 52 49 4E 54 A3 KEPRINT# C0F8 50 52 49 4E D4 43 4F 4E PRINTCON C100 D4 4C 49 53 D4 43 4C D2 TLISTCLR C108 43 4D C4 53 59 D3 4F 50 CMDSYSOP C110 45 CE 43 4C 4F 53 C5 47 ENCLOSEG C118 45 D4 4E 45 D7 54 41 42 ETNEWTAB C120 A8 54 CF 46 CE 53 50 43 (TOFNSPC C128 A8 54 48 45 CE 4E 4F D4 (THENNOT C130 53 54 45 D0 AB AD AA AF STEP+-*/ C138 DE 41 4E C4 4F D2 BE BD ^ANDOR>= C140 BC 53 47 CE 49 4E D4 41 <SGNINTA C148 42 D3 55 53 D2 46 52 C5 BSUSRFRE C150 50 4F D3 53 51 D2 52 4E POSSQRRN C158 C4 4C 4F C7 45 58 D0 43 DLOGEXPC C160 4F D3 53 49 CE 54 41 CE OSSINTAN C168 41 54 CE 50 45 45 CB 4C ATNPEEKL C170 45 CE 53 54 52 A4 56 41 ENSTR$VA C178 CC 41 53 C3 43 48 52 A4 LASCCHR$ C180 4C 45 46 54 A4 52 49 47 LEFT$RIG C188 48 54 A4 4D 49 44 A4 47 HT$MID$G C190 CF 00 G~
Meaning, including the terminating zero-byte, it’s exactly 255 bytes! In order to access this via a simple indexed read instruction, there was just enough space left to squeeze in the additional GO for version 2.0!
As the read index/cursor in Y wraps around on an overflow, this is perfectly in sync with the length of the list, which has exactly 76 entries. Thus, a character value of 77 lists as token 0x81, “FOR”, which is at index #1 in this list, and so on. Now we can perfectly understand how these “excess tokens” are expanded!
Demise
We still haven’t explained why SHIFT-L, PETSCII 0xCC, isn’t expanded to “END’, which is in zeroth position (0xCC-0x80=76, 76-76=0). Readers may turn their p.t. attention to what actually is in 77th position of our zero-base-indexed list: it’s the terminating zero-byte!
This may already give away that this might be about an uncaught edge-condition. Some guard isn’t what it ought to be. — And how does this manage to generate a “SYNTAX ERROR”?
The issue of the edge case is an easier one, let’s have a look at this, step by step:
- we read SHIFT-L,
0xCC, from the program. - it has the sign-bit set and is not “π”, thus it must be a token
- we subtract the sign-bit and add one, giving 77
- we skip 77-1 keywords, arriving at just before the terminating zero-byte
- we advance to the first character of the next one
- we read the zero-byte
- we output that zero-byte (will be ignored)
- if it’s non-zero, we branch unconditionally for the next keyword character…
Oops, this last assumption failed! Utterly! It’s not unconditional and we actually fall through!
This explains why it fails, but it doesn’t explain how it fails, namely with a syntax error!
For this, we need to take an even closer look, as in CPU trace, starting just after we skipped over the entire keyword list and load what is supposedly the first character of our keyword:
addr instr disass |AC XR YR SP|nvdizc| C64D C8 INY |CF 00 FE FA|010011| ;increment Y to first keyword char C64E B9 92 C0 LDA $C092,Y |CF 00 FF FA|110001| ;load it: 0x00 (terminating zero-byte) C651 30 B5 BMI $C608 |00 00 FF FA|010011| ;end of keyword? (no) C653 20 45 CA JSR $CA45 |00 00 FF FA|010011| ;output... ... ... RTS |00 00 FF FA|000010| ;...returns with A restored (0x00) C656 D0 F5 BNE $C64D |00 00 FF FA|000010| ;loop for next program byte (unless zero) C658 A9 80 LDA #$80 |00 00 FF FA|000010| ;outside of LIST routine C65A 85 0A STA $0A |80 00 FF FA|100000| ; -- " -- C65C 20 AD C8 JSR $C8AD |80 00 FF FA|100000| ; -- " -- ...
So, what is this “outside of LIST routine”, starting at $C658, as we fall through? And why should this cause a syntax error?
;end of LIST/UN-CRUNCH ... C653 20 45 CA JSR $CA45 ;output the character C656 D0 F5 BNE iC64D ;loop (really?) ;BASIC command `FOR` C658 A9 80 LDA #$80 C65A 85 0A STA $0A C65C 20 AD C8 JSR $C8AD ...
It’s the start of the FOR routine, which follows immediately after LIST in ROM!
This also proves that isn’t the output routine, which fails over the zero-byte, but the FOR routine, which is failing over another issue: as this starts its preparations, it eventually attempts to collect and parse its parameters, thus trying to access a context/state, which has been long consumed by the LIST routine. It’s thus the LIST routine, which throws the syntax error.
BASIC 4.0
Let’s repeat our earlier experiment with BASIC 4.0:
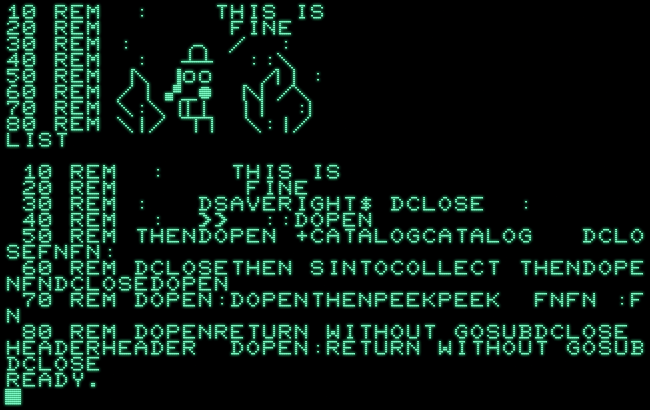
Well, this looks similar, but different: there are lots of disk commands, and what’s this, “RETURN WITHOUT GOSUB”, even twice? Clearly, this doesn’t wrap around like earlier versions. But, what does it do instead?
Let’s have a look at the keyword list of BASIC 4.0:
addr code petscii B0B2 45 4E C4 46 4F D2 ENDFOR B0B8 4E 45 58 D4 44 41 54 C1 NEXTDATA B0C0 49 4E 50 55 54 A3 49 4E INPUT.IN B0C8 50 55 D4 44 49 CD 52 45 PUTDIMRE B0D0 41 C4 4C 45 D4 47 4F 54 ADLETGOT B0D8 CF 52 55 CE 49 C6 52 45 ORUNIFRE B0E0 53 54 4F 52 C5 47 4F 53 STOREGOS B0E8 55 C2 52 45 54 55 52 CE UBRETURN B0F0 52 45 CD 53 54 4F D0 4F REMSTOPO B0F8 CE 57 41 49 D4 4C 4F 41 NWAITLOA B100 C4 53 41 56 C5 56 45 52 DSAVEVER B108 49 46 D9 44 45 C6 50 4F IFYDEFPO B110 4B C5 50 52 49 4E 54 A3 KEPRINT. B118 50 52 49 4E D4 43 4F 4E PRINTCON B120 D4 4C 49 53 D4 43 4C D2 TLISTCLR B128 43 4D C4 53 59 D3 4F 50 CMDSYSOP B130 45 CE 43 4C 4F 53 C5 47 ENCLOSEG B138 45 D4 4E 45 D7 54 41 42 ETNEWTAB B140 A8 54 CF 46 CE 53 50 43 (TOFNSPC B148 A8 54 48 45 CE 4E 4F D4 (THENNOT B150 53 54 45 D0 AB AD AA AF STEP+-*/ B158 DE 41 4E C4 4F D2 BE BD ^ANDOR>= B160 BC 53 47 CE 49 4E D4 41 <SGNINTA B168 42 D3 55 53 D2 46 52 C5 BSUSRFRE B170 50 4F D3 53 51 D2 52 4E POSSQRRN B178 C4 4C 4F C7 45 58 D0 43 DLOGEXPC B180 4F D3 53 49 CE 54 41 CE OSSINTAN B188 41 54 CE 50 45 45 CB 4C ATNPEEKL B190 45 CE 53 54 52 A4 56 41 ETSTR.VA B198 CC 41 53 C3 43 48 52 A4 LASCCHR$ B1A0 4C 45 46 54 A4 52 49 47 LEFT$RIG B1A8 48 54 A4 4D 49 44 A4 47 HT$MID$G B1B0 CF 43 4F 4E 43 41 D4 44 OCONCATD B1B8 4F 50 45 CE 44 43 4C 4F OPENDCLO B1C0 53 C5 52 45 43 4F 52 C4 SERECORD B1C8 48 45 41 44 45 D2 43 4F HEADERCO B1D0 4C 4C 45 43 D4 42 41 43 LLECTBAC B1D8 4B 55 D0 43 4F 50 D9 41 KUPCOPYA B1E0 50 50 45 4E C4 44 53 41 PPENDDSA B1E8 56 C5 44 4C 4F 41 C4 43 VEDLOADC B1F0 41 54 41 4C 4F C7 52 45 ATALOGRE B1F8 4E 41 4D C5 53 43 52 41 NAMESCRA B200 54 43 C8 44 49 52 45 43 TCHDIREC B208 54 4F 52 D9 00 TORY~
The keyword list has been amended for BASIC 4.0 to include various disk commands and is clearly longer than 256 bytes. Therefor, BASIC 4.0 has to use a more complex construct to access the list, involving a zero-page pointer, just as we have seen it in the tokenizer routine (of which this is — in principle — the reverse.) As a consequence it has much more tokens to play with, as seen in our “This is fine” example.
But, what happens, if we read beyond this list, if we won’t wrap around?
Well, the skip-search spills over into what follows immediately after this in ROM, which happens to be:
addr code petscii B20D .. .. .. .. .. 4E 45 58 NEX B210 54 20 57 49 54 48 4F 55 T WITHOU B218 54 20 46 4F D2 53 59 4E T FORSYN B220 54 41 D8 52 45 54 55 52 TAXRETUR B228 4E 20 57 49 54 48 4F 55 N WITHOU B230 54 20 47 4F 53 55 C2 4F T GOSUBO B238 55 54 20 4F 46 20 44 41 UT OF DA B240 54 C1 49 4C 4C 45 47 41 TZILLEGA B248 4C 20 51 55 41 4E 54 49 L QUANTI B250 54 D9 4F 56 45 52 46 4C TYOVERFL B258 4F D7 4F 55 54 20 4F 46 OWOUT OF B260 20 4D 45 4D 4F 52 D9 55 MEMORYU B268 4E 44 45 46 27 44 20 53 NDEF'D S B270 54 41 54 45 4D 45 4E D4 TATEMENT B278 42 41 44 20 53 55 42 53 BAD SUBS B280 43 52 49 50 D4 52 45 44 CRIPTRED B288 49 4D 27 44 20 41 52 52 IM'D ARR B290 41 D9 44 49 56 49 53 49 AYDIVISI B298 4F 4E 20 42 59 20 5A 45 ON BY ZE B2A0 52 CF 49 4C 4C 45 47 41 ROILLEGA B2A8 4C 20 44 49 52 45 43 D4 L DIRECT B2B0 54 59 50 45 20 4D 49 53 TYPE MIS B2B8 4D 41 54 43 C8 53 54 52 MATCHSTR B2C0 49 4E 47 20 54 4F 4F 20 ING TOO B2C8 4C 4F 4E C7 46 49 4C 45 LONGFILE B2D0 20 44 41 54 C1 46 4F 52 DATAFOR B2D8 4D 55 4C 41 20 54 4F 4F MULA TOO B2E0 20 43 4F 4D 50 4C 45 D8 COMPLEX B2E8 43 41 4E 27 54 20 43 4F CAN'T CO B2F0 4E 54 49 4E 55 C5 55 4E NTINUEUN B2F8 44 45 46 27 44 20 46 55 DEF'D FU B300 4E 43 54 49 4F CE 20 45 NCTION E B308 52 52 4F 52 00 RROR~
It’s the list of error messages, which — for menace or luck — is encoded just in the same way!
If we’re out of keywords, these will do, as well.
Because of this, BASIC 4.0 will spell shifted/upper-case “COMMODORE” in remarks slightly differently, as in “lenrecorddopendopenrecordstr$backupval“.
Now that we know this crucial fact, we may turn our attention wholeheartedly to:
Beyond the PET — Commodore BASIC V.2 (VIC-20, C64…)
The LIST routine of BASIC V.2 is very similar to the “New ROM” of the PET 2001:
PET 2001 “New ROM” ;command LIST C5B5 BCC iC5BD C5B7 BEQ iC5BD C5B9 CMP #$AB C5BB BNE $C5A6 C5BD iC5BD JSR $C873 C5C0 JSR $C52C C5C3 JSR $0076 C5C6 BEQ iC5D4 C5C8 CMP #$AB C5CA BNE $C55A C5CC JSR $0070 C5CF JSR $C873 C5D2 BNE $C55A C5D4 iC5D4 PLA C5D5 PLA C5D6 LDA $11 C5D8 ORA $12 C5DA BNE iC5E2 C5DC LDA #$FF C5DE STA $11 C5E0 STA $12 C5E2 iC5E2 LDY #$01 C5E4 STY $09 C5E6 LDA ($5C),Y C5E8 BEQ iC62D C5EA JSR $FFE1 C5ED JSR $C9E2 C5F0 INY C5F1 LDA ($5C),Y C5F3 TAX C5F4 INY C5F5 LDA ($5C),Y C5F7 CMP $12 C5F9 BNE iC5FF C5FB CPX $11 C5FD BEQ iC601 C5FF iC5FF BCS iC62D C601 iC601 STY $46 C603 JSR $DCD9 C606 LDA #$20 C608 iC608 LDY $46 C60A AND #$7F C60C iC60C JSR $CA45 C60F CMP #$22 C611 BNE iC619 C613 LDA $09 C615 EOR #$FF C617 STA $09 C619 iC619 INY C61A BEQ iC62D C61C LDA ($5C),Y C61E BNE iC630 C620 TAY C621 LDA ($5C),Y C623 TAX C624 INY C625 LDA ($5C),Y C627 STX $5C C629 STA $5D C62B BNE iC5E2 C62D iC62D JMP $C389 ;UN-CRUNCH C630 iC630 BPL iC60C C632 CMP #$FF C634 BEQ iC60C C636 BIT $09 C638 BMI iC60C C63A SEC C63B SBC #$7F C63D TAX C63E STY $46 C640 LDY #$FF C642 iC642 DEX C643 BEQ iC64D C645 iC645 INY C646 LDA $C092,Y C649 BPL iC645 C64B BMI iC642 C64D iC64D INY C64E LDA $C092,Y C651 BMI iC608 C653 JSR $CA45 C656 BNE iC64D
C64 Kernal Rev. 2 ;command LIST A69C BCC iA6A4 A69E BEQ iA6A4 A6A0 CMP #$AB A6A2 BNE $A68D A6A4 iA6A4 JSR $A96B A6A7 JSR $A613 A6AA JSR $0079 A6AD BEQ iA6BB A6AF CMP #$AB A6B1 BNE $A641 A6B3 JSR $0073 A6B6 JSR $A96B A6B9 BNE $A641 A6BB iA6BB PLA A6BC PLA A6BD LDA $14 A6BF ORA $15 A6C1 BNE iA6C9 A6C3 LDA #$FF A6C5 STA $14 A6C7 STA $15 A6C9 iA6C9 LDY #$01 A6CB STY $0F A6CD LDA ($5F),Y A6CF BEQ iA714 A6D1 JSR $A82C A6D4 JSR $AAD7 A6D7 INY A6D8 LDA ($5F),Y A6DA TAX A6DB INY A6DC LDA ($5F),Y A6DE CMP $15 A6E0 BNE iA6E6 A6E2 CPX $14 A6E4 BEQ iA6E8 A6E6 iA6E6 BCS iA714 A6E8 iA6E8 STY $49 A6EA JSR $BDCD A6ED LDA #$20 A6EF iA6EF LDY $49 A6F1 AND #$7F A6F3 iA6F3 JSR $AB47 A6F6 CMP #$22 A6F8 BNE iA700 A6FA LDA $0F A6FC EOR #$FF A6FE STA $0F A700 iA700 INY A701 BEQ iA714 A703 LDA ($5F),Y A705 BNE iA717 A707 TAY A708 LDA ($5F),Y A70A TAX A70B INY A70C LDA ($5F),Y A70E STX $5F A710 STA $60 A712 BNE iA6C9 A714 iA714 JMP $E386 ;UN-CRUNCH A717 iA717 JMP ($0306) ;defaults to $A71A A71A BPL iA6F3 A71C CMP #$FF A71E BEQ iA6F3 A720 BIT $0F A722 BMI iA6F3 A724 SEC A725 SBC #$7F A727 TAX A728 STY $49 A72A LDY #$FF A72C iA72C DEX A72D BEQ iA737 A72F iA72F INY A730 LDA $A09E,Y A733 BPL iA72F A735 BMI iA72C A737 iA737 INY A738 LDA $A09E,Y A73B BMI iA6EF A73D JSR $AB47 A740 BNE iA737
As we may observe, the two versions are nearly indentical, but for a single addition: instead of directly proceeding with UN-CRUNCH-ing, the C64 version takes an indirect jump via a vector at $0306, which is set by default to the very next address, $A71A. This newly introduced indirection allows BASIC extensions to plug-in their own UN-CRUNCH routine, in order to expand any additional tokens.
C64 Kernal Rev. 3
And Kernal Rev. 3? Well, it’s exactly the same, but addresses differ a little, as the routine has moved in ROM:
C64 Kernal Rev. 2 ;command LIST A69C BCC iA6A4 A69E BEQ iA6A4 A6A0 CMP #$AB A6A2 BNE $A68D A6A4 iA6A4 JSR $A96B A6A7 JSR $A613 A6AA JSR $0079 A6AD BEQ iA6BB A6AF CMP #$AB A6B1 BNE $A641 A6B3 JSR $0073 A6B6 JSR $A96B A6B9 BNE $A641 A6BB iA6BB PLA A6BC PLA A6BD LDA $14 A6BF ORA $15 A6C1 BNE iA6C9 A6C3 LDA #$FF A6C5 STA $14 A6C7 STA $15 A6C9 iA6C9 LDY #$01 A6CB STY $0F A6CD LDA ($5F),Y A6CF BEQ iA714 A6D1 JSR $A82C A6D4 JSR $AAD7 A6D7 INY A6D8 LDA ($5F),Y A6DA TAX A6DB INY A6DC LDA ($5F),Y A6DE CMP $15 A6E0 BNE iA6E6 A6E2 CPX $14 A6E4 BEQ iA6E8 A6E6 iA6E6 BCS iA714 A6E8 iA6E8 STY $49 A6EA JSR $BDCD A6ED LDA #$20 A6EF iA6EF LDY $49 A6F1 AND #$7F A6F3 iA6F3 JSR $AB47 A6F6 CMP #$22 A6F8 BNE iA700 A6FA LDA $0F A6FC EOR #$FF A6FE STA $0F A700 iA700 INY A701 BEQ iA714 A703 LDA ($5F),Y A705 BNE iA717 A707 TAY A708 LDA ($5F),Y A70A TAX A70B INY A70C LDA ($5F),Y A70E STX $5F A710 STA $60 A712 BNE iA6C9 A714 iA714 JMP $E386 ;UN-CRUNCH A717 iA717 JMP ($0306) ;defaults to $A71A A71A BPL iA6F3 A71C CMP #$FF A71E BEQ iA6F3 A720 BIT $0F A722 BMI iA6F3 A724 SEC A725 SBC #$7F A727 TAX A728 STY $49 A72A LDY #$FF A72C iA72C DEX A72D BEQ iA737 A72F iA72F INY A730 LDA $A09E,Y A733 BPL iA72F A735 BMI iA72C A737 iA737 INY A738 LDA $A09E,Y A73B BMI iA6EF A73D JSR $AB47 A740 BNE iA737
C64 Kernal Rev. 3 ;command LIST A698 BCC iA6A0 A69A BEQ iA6A0 A69C CMP #$AB A69E BNE $A689 A6A0 iA6A0 JSR $A96B A6A3 JSR $A613 A6A6 JSR $0079 A6A9 BEQ iA6B7 A6AB CMP #$AB A6AD BNE $A63D A6AF JSR $0073 A6B2 JSR $A96B A6B5 BNE $A63D A6B7 iA6B7 PLA A6B8 PLA A6B9 LDA $14 A6BB ORA $15 A6BD BNE iA6C5 A6BF LDA #$FF A6C1 STA $14 A6C3 STA $15 A6C5 iA6C5 LDY #$01 A6C7 STY $0F A6C9 LDA ($5F),Y A6CB BEQ iA710 A6CD JSR $A82C A6D0 JSR $AAD7 A6D3 INY A6D4 LDA ($5F),Y A6D6 TAX A6D7 INY A6D8 LDA ($5F),Y A6DA CMP $15 A6DC BNE iA6E2 A6DE CPX $14 A6E0 BEQ iA6E4 A6E2 iA6E2 BCS iA710 A6E4 iA6E4 STY $49 A6E6 JSR $BDCD A6E9 LDA #$20 A6EB iA6EB LDY $49 A6ED AND #$7F A6EF iA6EF JSR $AB47 A6F2 CMP #$22 A6F4 BNE iA6FC A6F6 LDA $0F A6F8 EOR #$FF A6FA STA $0F A6FC iA6FC INY A6FD BEQ iA710 A6FF LDA ($5F),Y A701 BNE iA713 A703 TAY A704 LDA ($5F),Y A706 TAX A707 INY A708 LDA ($5F),Y A70A STX $5F A70C STA $60 A70E BNE iA6C5 A710 iA710 JMP $E386 ;UN-CRUNCH A713 iA713 JMP ($0306) ;defaults to $A716 A716 BPL iA6EF A718 CMP #$FF A71A BEQ iA6EF A71C BIT $0F A71E BMI iA6EF A720 SEC A721 SBC #$7F A723 TAX A724 STY $49 A726 LDY #$FF A728 iA728 DEX A729 BEQ iA733 A72B iA72B INY A72C LDA $A09E,Y A72F BPL iA72B A731 BMI iA728 A733 iA733 INY A734 LDA $A09E,Y A737 BMI iA6EB A739 JSR $AB47 A73C BNE iA733
Well, that’s that. Now we have seen about all, there is to see. — But we’re not finished, yet.
LIST’s Reform
The indirection introduced in Commodore BASIC V.2 allows us to sketch out a patch that would actually fix the issues with REM in LIST.
As every program byte is handled by UN-CRUNCH before output, we may introduce a quick check for the token value of REM. If it’s not REM, we jump to the stock UN-CRUNCH routine. If it is, we divert to a path of our own, where we output the keyword (no need to go over the list for this) and then output the rest the line in a tight loop.
E.g., by something along those lines:
;LIST REM-fix sketch, C64 Kernal Rev.2 ;we get here from $A717 via the jump vector at $0306 CMP #$8F ;is it REM? BEQ skip ;yes, skip next JMP $A71A ;continue with normal UN-CRUNCH skip LDA #$52 ;print `R` JSR $AB47 LDA #$45 ;print `E` JSR $AB47 LDA #$4D ;print `M` JSR $AB47 loop INY ;advance cursor BEQ finish ;check overflow (line too long) LDA ($5F),Y ;get next char BEQ iseol ;check for EOL JSR $AB47 ;print it BNE loop ;next char (unconditional) iseol JMP $A707 ;to LIST EOL-code… finish JMP $E386 ;BASIC warm start
DISCLAIMER: This is just a sketch and entirely untested!
Mind that Kernal addresses will differ with Kernal/ROM revisions.
For Kernal Rev. 3, with the system addresses adapted, it should be something like this:
;LIST REM-fix sketch, C64 Kernal Rev.3 ;we get here from $A713 via the jump vector at $0306 CMP #$8F ;is it REM? BEQ skip JMP $A716 ;UN-CRUNCH skip LDA #$52 JSR $AB47 LDA #$45 JSR $AB47 LDA #$4D JSR $AB47 loop INY BEQ finish LDA ($5F),Y BEQ iseol JSR $AB47 BNE loop iseol JMP $A703 ;LIST EOL-code… finish JMP $E386
DISCLAIMER: This is just a sketch and entirely untested!
Mind that Kernal addresses will differ with Kernal/ROM revisions.
But it’s also here that we can discern a conceptual blemish in this plug-in concept: while other routines, like the routine for outputting a character (at $AB47), are at invariable addresses, the LIST routine is not, nor is UN-CRUNCH. But, since this is not a subroutine, we’ll have to hand over to the stock UN-CRUNCH eventually, or, if we were to replace UN-CRUNCH enterily, jump back to the entracnce of the character loop in the LIST routine — and these addresses vary with Kernal revisions by a few bytes. Meaning, any BASIC extensions making use of this or even a small patch, like this one, will have to come in multiple versions, even for a machine, which is as monolithic as the C64 is.
(A way around the problem of the moving jump targets for any LIST extensions may be to store whatever we initially found in $0306 somewhere and to calculate jump addresses from relative offsets from there and store this in another two bytes as avector for an indirect jump instruction and then return to the originally routine by this additional step of indirection. But this will require us to find at least 4 otherwise unused and safe bytes in the already crowded system RAM area. Or you could use the RAM at $C000 for this, as a proper extension will probably use this anyways. But the problem remains: If we want to read till the end of the line, and not just handle custom tokens, we need to jump back into the code before UN-CRUNCH, because this doesn’t handle a terminating zero-byte, rather assuming that this would have been caught already.)
LIST’s Defeat
Until now, we’ve always stressed that BASIC programs are forward-linked lists. And, as we’ve seen, this is perfectly true for the LIST command: it pulls itself along, from line link to line link. As it encounters an end-of-line marker, it reads the address of the next line from the very beginning of the current line from memory and sets this as the new base pointer for the next iteration.
This is not as much true for the BASIC runtime, though. Since the editor always reorders the program in memory on any edit, the program text should be always linear, without any gaps, and always in strict order of the line numbers. Therfore, in any linear context, the runtime, whenever it encounters an end-of-line (a zero-byte), assumes that what follows in memory must be the next line. It “knows” that the next two bytes are the line-link and the next two after this must be the line number and that the 5th byte into this is the start of the actual program text (there is no such thing as an entirely empy line).
Thus, it just inspects the high-byte of the link for a zero-byte, indicative of the end of the program text. But it ignores it otherwise and skips over this, since it already “knows” its current position in memory. Line links are still crucial for searching line targets, as for GOTO and GOSUB. But in linear context, even for FOR…NEXT loops or for finding DATA sections, not so much.
We can (ab)use this incongruency in how program sequence is handled by LIST and by the runtime to hide any number of lines from LIST, by this defeating it for the purpose of inspection and giving away our precious code to nosy users: by manipulating the line links. The runtime will still churn along happily, as long as this doesn’t involve any GOTOs, GOSUBs, or related targets inside this section. (But we may still jump around this.)
All we need to do is to manipulate the line link(s) to exclude whatever amount of lines, we want to hide.
E.g., the following short program
10 A=1 15 A=200 20 PRINT A*A
is stored in memory (here on a PET with programs starting in memory at $0401) as
addr code petscii 0401 09 04 0A 00 41 B2 31 ....A.1 0408 00 13 04 0F 00 41 B2 32 .....A.2 0410 30 30 00 1D 04 14 00 99 00...... 0418 20 41 AC 41 00 00 00 A.A... (marked bytes are the line links)
or, disassembled:
addr code semantics 0401 09 04 link: $0409 0403 0A 00 line# 10 0405 41 ascii «A» 0406 B2 token = 0407 31 ascii «1» 0408 00 -EOL- 0409 13 04 link: $0413 040B 0F 00 line# 15 040D 41 ascii «A» 040E B2 token = 040F 32 30 30 ascii «200» 0412 00 -EOL- 0413 1D 04 link: $041D 0415 14 00 line# 20 0417 99 token PRINT 0418 20 41 ascii « A» 041A AC token * 041B 41 ascii «A» 041C 00 -EOL- 041D 00 00 -EOT-
If we want to hide line #15 from our users, all we have to do is replacing the line link for line #10 by a pointer to line #20, as found in the link to the next line for line #15:
addr code petscii 0401 13 04 0A 00 41 B2 31 ....A.1 0408 00 13 04 0F 00 41 B2 32 .....A.2 0410 30 30 00 1D 04 14 00 99 00...... 0418 20 41 AC 41 00 00 00 A.A...
or, in disassmbly:
addr code semantics 0401 09 04 link: $0413 memory address of line #20! 0403 0A 00 line# 10 0405 41 ascii «A» 0406 B2 token = 0407 31 ascii «1» 0408 00 -EOL- 0409 13 04 link: $0413 now hidden! 040B 0F 00 line# 15 040D 41 ascii «A» 040E B2 token = 040F 32 30 30 ascii «200» 0412 00 -EOL- 0413 1D 04 link: $041D LIST continues here 0415 14 00 line# 20 0417 99 token PRINT 0418 20 41 ascii « A» 041A AC token * 041B 41 ascii «A» 041C 00 -EOL- 041D 00 00 -EOT-
If we list our pragram now, it looks — quite inconspicuously — like this:
10 A=1 20 PRINT A*A
But, if we run it, line #15 (“A=200”) will be still executed — and math will be apparently not what it used to be:
LIST 10 A=1 20 PRINT A*A READY. RUN 40000 READY. █
LIST will still work as expected, while ignoring line #15
LIST 15 READY. LIST 15- 20 PRINT A*A READY. █
And here’s a screenshot of our proof of concept:
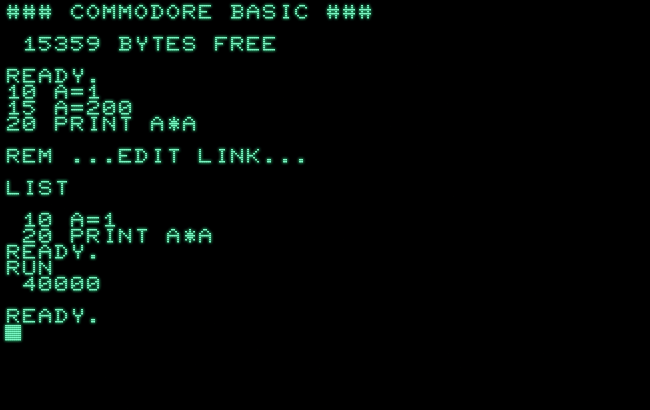
And, of course, this will not only work for just a single line, but for any amount of lines.
However, this defeat will not be a final one:
Whenever we load such a manipulated program as a BASIC program, the program is handled similar to input, enforcing a tight in-order sequence in memory, which also involves a relinking of the lines. — And so, fear not, dear reader, the once hidden lines will LIST again and no malicious code will be hidden from your eyes.
(Meaning, for a normal BASIC program, the effect can only be achieved, once the program has already been entered or loaded in its final form, by a POKE at run-time.)
And that’s it, for today.
Norbert Landsteiner,
Vienna, 2025-07-08