Virtual 6502 — Update Round 2
Another major update to the venerable “Virtual 6502” emulator – assembler – disassembler suite.

I may have been a bit unresponsive over the last few days, but there is a reason for this. Namely, I invested most of my available time into another round of updates to the “Virtual 6502” suite, consisting of an emulator of the MOS 6502 MPU, an old-school assembler, and a respective disassembler. And this has been a major round of updates. Suffice to say, I think these venerable programs, which had been a bit basic and even dated by now, do now for a competent little suite of programs.
To begin with, all the apps now support “illegal opcodes“. To be more precise, the implementation adheres to No More Secrets (v.091, 24 December 2016 release), which is also consistent with Graham's opcode table and the vericfication by visual6502.org.
Let’s a have a quick tour around these apps.
The Emulator
The emulator is the traditional pièce de résistance of the Virtual 6502 suite. Hence, it has received some extra care. First of all, the CPU core enjoyed a major rewrite and reorganisation of the code. (There isn’t much left of the original implementation, which is still listed in the credits.) Moreover, in order to make this a versatile pice of software, the interctive part has been substantially overhauled as well.
Here are all the additions at a glance:
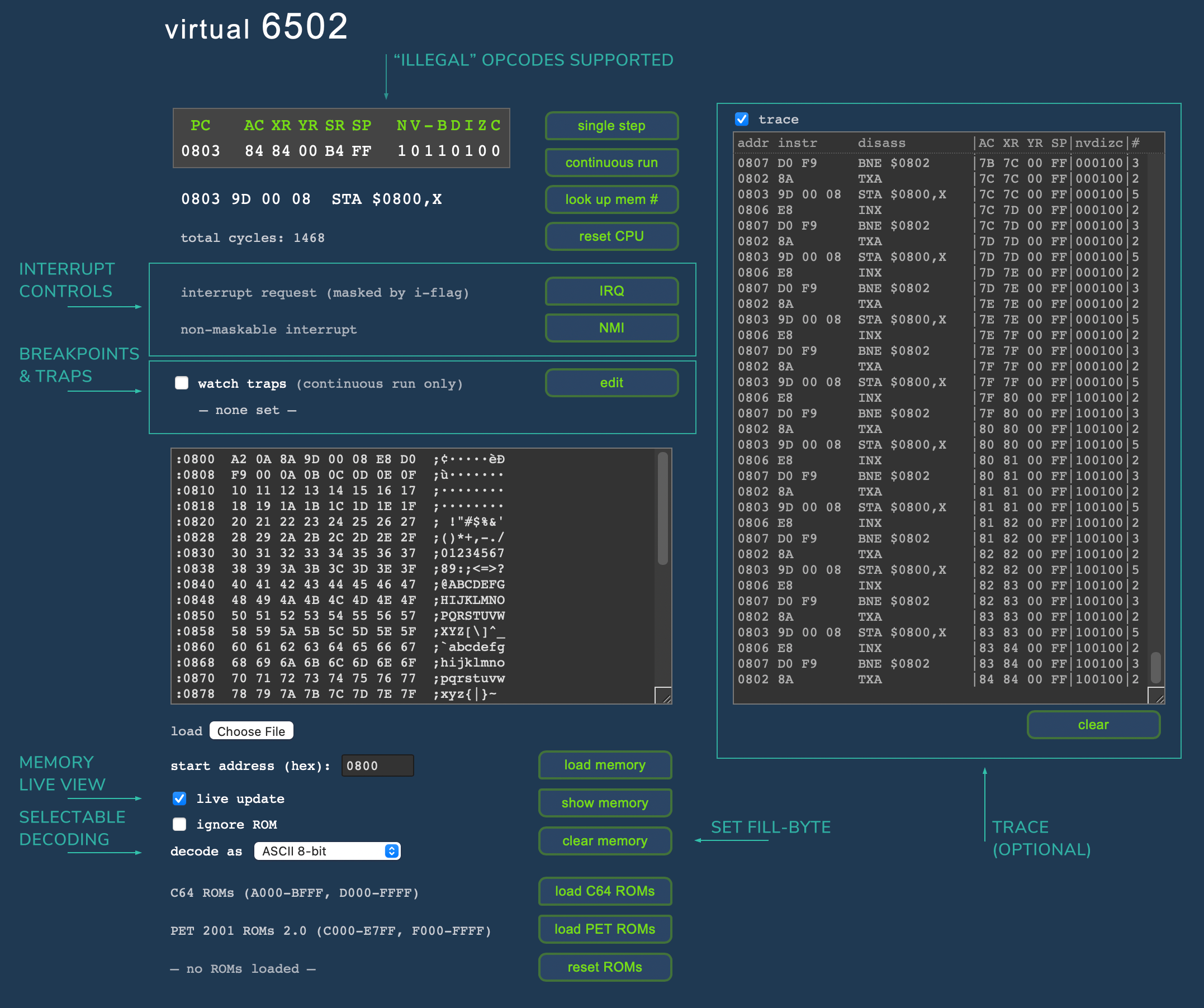
Here’s a quick overview over the newly added and extended features:
- CPU Core: As already mentioned, we now support “illegal opcodes” out-of-the-box, including the infamous “
JAM” instruction (you will have to reset the CPU). Mnemonics of illegal opcodes are prefixed by an asterisk (“*”) anywhere they may occur (i.e., in the disassembly of the next instruction below the register display and in the trace output) for a quick distinction. - Trace: This may be the most versatile addition: a complete trace of instructions, state of registers (as of after the execution of the respective instruction), and cycle counts. In order to keep the UI simple, this is hidden behind a checkbox by default.
- Interrupts: You may now manually trigger interrupts, which will cause the CPU to halt (if in continuous run mode) and trigger an informative dialog (listing where an interrupt occured and which jump vector was taken to what address). This also applies to “
BRK” instructions. - Breakpoints & Traps let you monitor the CPU in continuous run mode. Watchdogs may be set for breakpoints, register values (equal, greater than or less than a given value), or stack pointer over- and underflows. Multiple traps/breakpoints may be set and enabled/disabled globally and on an individual basis.
- Live Memory View: This provides a live view into a selected page (256 bytes) of memory. While the emulator doesn’t feature any screen emulation (as it doesn’t favor any particular hardware implementation), this makes up for it to some extent, as far as text output is concerned.
- Selectable Character Translation: To make this even more versatile, you may select the character encoding for the text translation of the memory view, anything of ASCII 7-bit (US-ASCII), ASCII 8-bit, PETSCII, CBM 8-bit screen codes (both in variants for early PETs and later, more common Commodore machines).
- Speaking of Commodore machines, these use special fill-bytes for prefilling memory locations, like
$EA(C64) or$AA(PET). Now you can emulate this, as well, by setting a custom fill-byte, when clearing the memory.
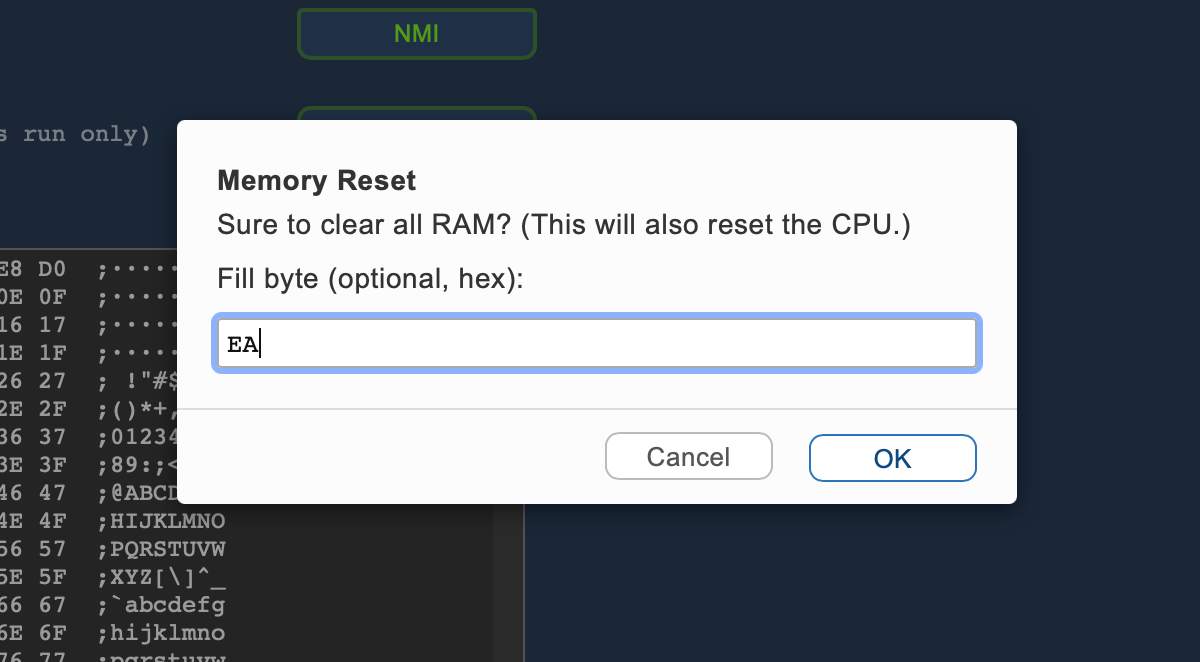
(The operabilty of our custom dialogs has been improved, as well.)
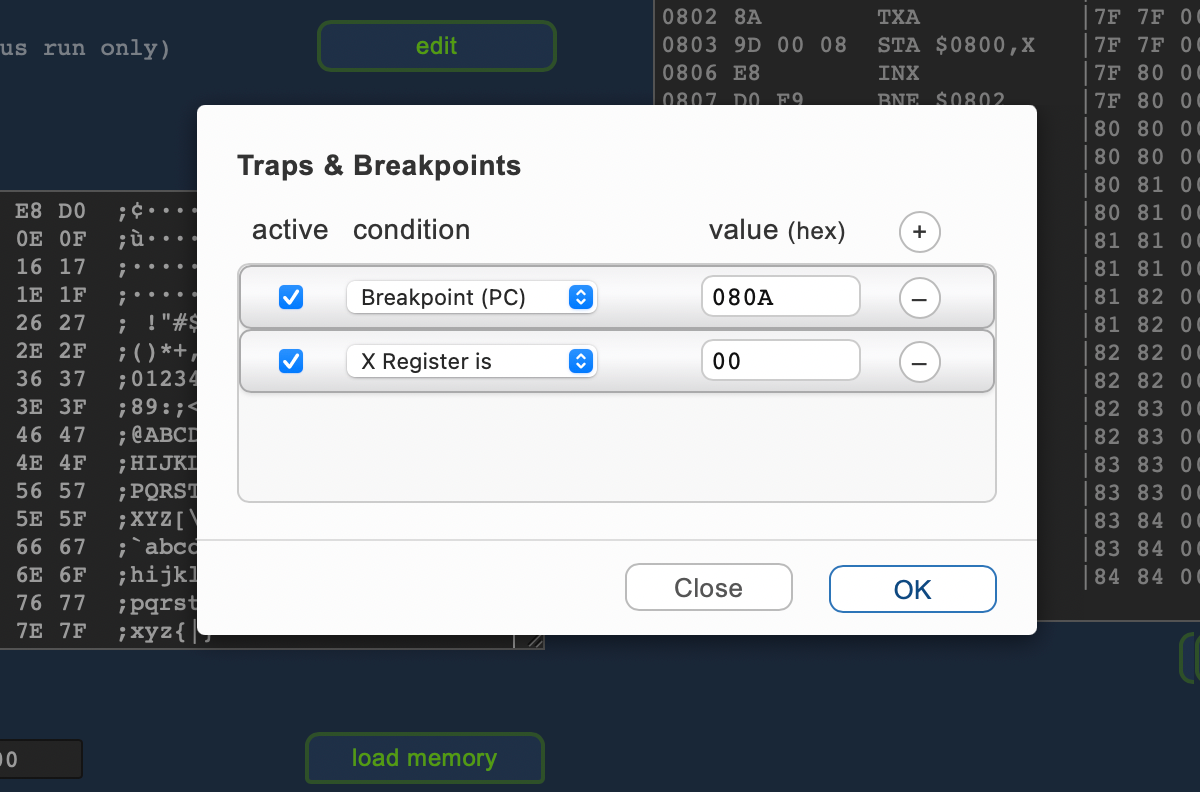
Mind that this is still not a full IDE (a bit of interoperability with the assembler has been added, though — see below), nor a full-fledged emulation of a real or fantasy 8-bit machine. This isn’t really its goal or purpose. Think more of it as one of the chip trainers of the 1970s (like the Commodore KIM-1, or the Acorn System 1), letting you inspect and explore the behavior of the CPU under particular circumstances, both in single steps and over more extensive runs.
Update (June 27, 2021)
We now also provide options to load the KIM-1 ROM and to appropriately emulate the ROR-bug of the pre-June 1976 production series. (Officially, while documented, the instruction was “not yet implemented”. In actuality there was a bug in the PLA lines decoding the instruction and ROR behaved like ASL, but always shifted in zero and preserved the carry-flag.)
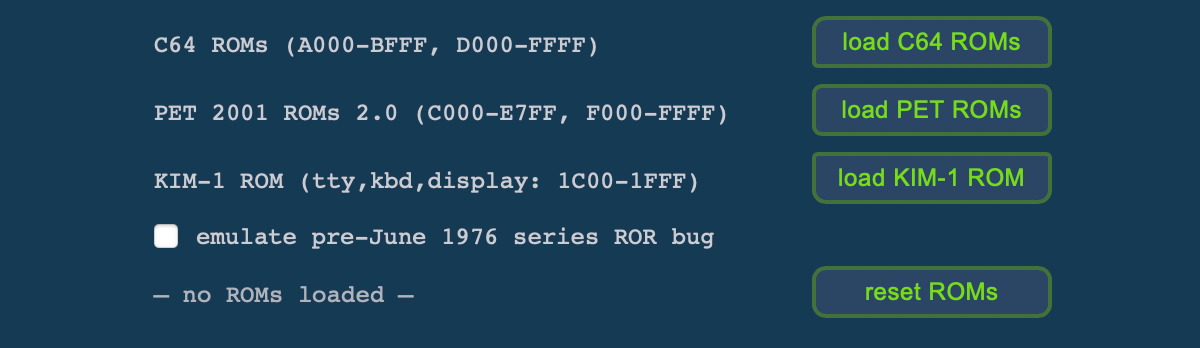
(The ROR-bug emulation works without the KIM-1 ROM, as well.)
The Assembler
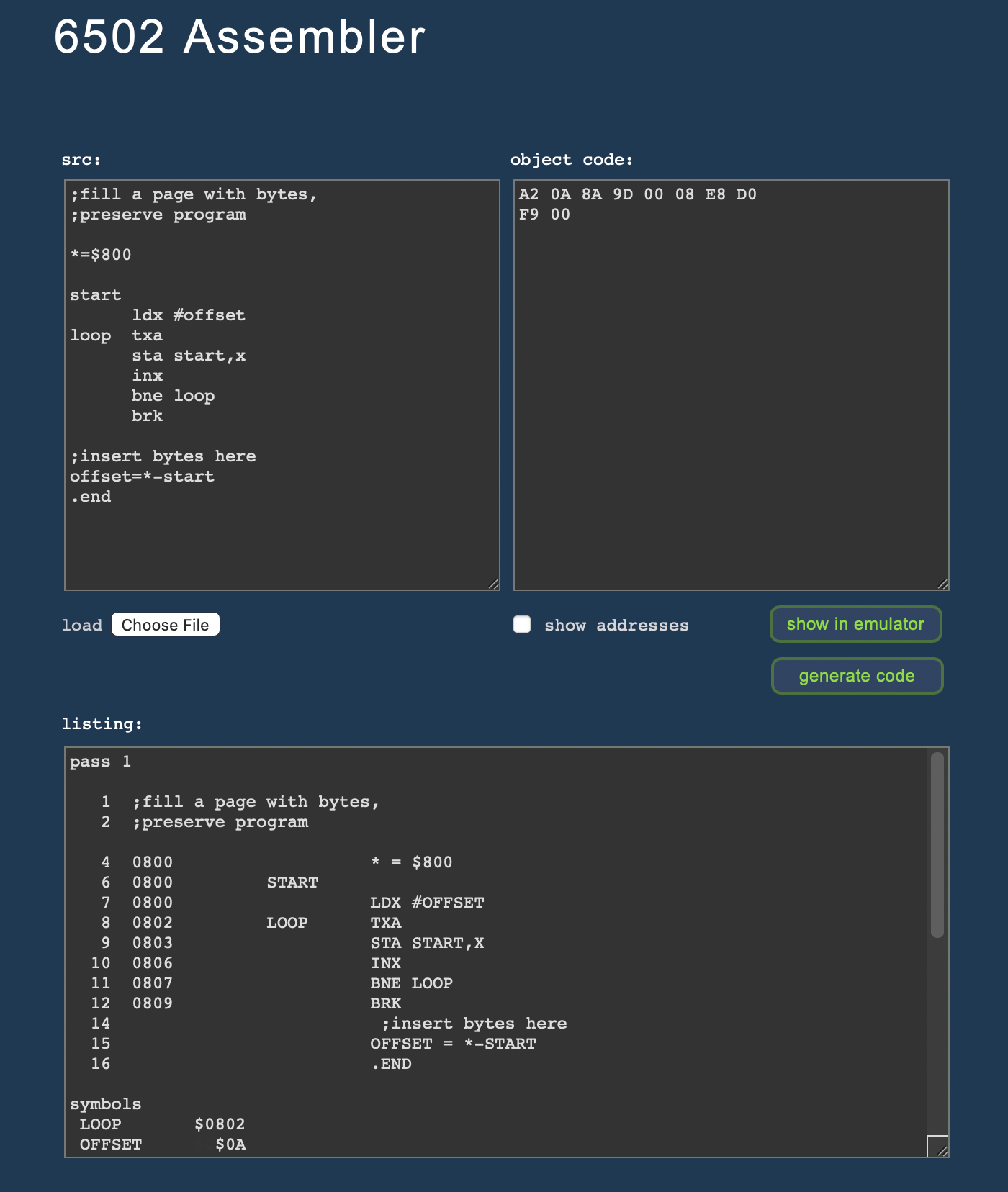
The assembler enjoyed a major overhaul, as well. As major hightlights, we now support illegal opcodes (optional, activated by the pragma/pseudo-instruction “.OPT ILLEGALS”) and complex expressions.
Moreover, the list output has been reorganized and now reflects much better how the source is processed and presents any errors in a more accurate way. The listing of pass 1 now represents the source as “seen” by the assembler (together with line numbers and instruction addresses), while the second pass represents the code as processed, with inserted values and in normalized notation.
The “native format” of the assembler is close to the original MOS assembler. However, where this uses “LDY (AA)Y” for indirect, Y-indexed address modes, we default to the more common notation including a comma, as in “LDY (AA),Y”. The original MOS format is still recognized, as well as many other syntax variations.
E.g., compare this little program:
;fill a page with bytes,
;preserve program
*=$800
start
ldx #offset
loop txa
sta start,x
inx
bne loop
brk
;insert bytes here
offset=*-start
.end
and its respective list output:
pass 1
1 ;fill a page with bytes,
2 ;preserve program
4 0800 * = $800
6 0800 START
7 0800 LDX #OFFSET
8 0802 LOOP TXA
9 0803 STA START,X
10 0806 INX
11 0807 BNE LOOP
12 0809 BRK
14 ;insert bytes here
15 OFFSET = *-START
16 .END
symbols
LOOP $0802
OFFSET $0A
START $0800
pass 2
;fill a page with bytes,
;preserve program
0800 * = $0800
0800 START
0800 A2 0A LDX #$0A
0802 8A LOOP TXA
0803 9D 00 08 STA $0800,X
0806 E8 INX
0807 D0 F9 BNE $0802
0809 00 BRK
;insert bytes here
OFFSET = $000A
.END
done (code: 0800..0809).
Mind the expression “OFFSET = *-START” at line 15: you may now use the special symbol “*” for the current address (you may still assign to “.ORG” and/or “.RORG”) anywhere in an expression.
Fun Question
What does
* = ***
do?
Answer
Well, ist sets the current address to its square (PC = PC * PC). Had it been 0x0004 before, it’s now 0x0010 (dec.16).
But isn’t this ambiguous? How does this work?
Now, the emulator supports the following features for expressions:
- Ary arithmetic operators, without precedence, solved left to right (as common with assemblers):
+… addition−… subtraction*… multiplication/… integer division
- Unary (prefix) operators:
−… unary minus<… low-byte operator>… high.byte operatory
- Grouping (using square brackets, groups may not be empty):
[… start of a group (open)]… group end (close)
- Values, any of
- Symbols/identifiers (8 significant characters, starting with
[A-Z]or underscore, continuing with[A-Z0-9_].) - Numbers, any of:
- decimal:
[0-9]+,0d[0-9]+ - binary:
%[01]+,0b[01]+ - octal:
@[0-7]+,0[0-7]+,0o[0-7]+ - hex:
$[0-9A-F]+,&[0-9A-F]+,0x[0-9A-F]+
(values declared by 4 hex digits are always considered of word-size)
- decimal:
- Symbols/identifiers (8 significant characters, starting with
Since we are not dealing with precedence (aside from unary prefix operators), we do not have to construct a complex, abstract syntax tree (AST) for expression, terms and factors, and using an arithmetic stack for resolving it. Rather, we can parse these neatly into a flat stack with a single result, using substacks for any groups to be solved in a recursive call.
This is equivalent to a simple state machine:
| state: | 0 | → | 1 | → | 2 | → | 0 |
| type: | unary operator (optional, multiple) | value (required) | ary operator (required or stop) | ||||
| token: | unary minus low-byte operator high-byte operator | number identifier * | additionsubtraction multiplication division ] end | ||||
| groups: | ↓ state: 0 | … | state: 1 ↑ | ||||
| solving: | store | apply unary apply to result | store |
It can be shown that an expression is only valid, if it consists of at least one value (required) and stops at state #2. Only state #0 is optional, but may contain multiple ary operators (as in “<-1”, i.e. the low-byte of negative 1, which is 0xFF). There is no way to mistake the symbol “*” for the ary operator “*”.
Solving stacks and substacks is easy enough:
- If we encounter an unary operator, we take note of the state/operation to be applied to the next value; which must follow in the next state.
- Is the next value a substack, we solve this one first and apply said ary operators (if any). Otherwise it must be a numeric value or an identifier, which are resolved with any unary operators applied, as well.
- Finally, if we encounter an ary operator, we take note of this one, as well, and, as we encounter the next value, we use this to form the new result. From state #2, we transition back to state #0, again.
Since a stack must eventually advance to state #1 and must also exit in state #1, and this is also the sole state, where any operations are applied, there is also no way we may miss an operation.
We may see, how lean this is on resources and why this is commonly used by assemblers, especially, if groups are omitted, which would allow us to solve the expression in place (instead of introducing some kind of hierarchy, requiring extra storage of sorts).
This mechanism also allows us to improve the detection of zeropage address modes by tainting any values and declarations of word-size or word-format.
E.g.,
A = $04 ; byte-size B = $0004 ; word-size (4 hex digits!) LDA A+2 ; zeropage LDA B+2 ; absolute (tainting propagated from symbol "B")
But:
C = $0480 ; word-size LDA <[C+2] ; low-byte operator –> zeropage
If a symbol is unknown at pass 1, word-size is assumed (since we have to determine addresses at this stage), and we may wait for pass 2, whether the symbol will finally resolve (since it is defined later in the code) or not. However, if we assign to the current address symbol (“*”) and any symbol involved is undefined, we encounter an error in pass 1, since the address can't be determined. (This could be solved by applying another pass, but this really beyond the scope of a relatively simple assembler.)
When an address is eventually evaluated to determine address modes, the following rules apply:
- Forced notation:
- If a load or store instructions is written in explicite byte-length notation (either using the “
.b” extension to the mnemonic, as with more modern assemblers, or using the “*” prefix to the address, as with older assemblers), the address will be of byte-length (zeropage) and truncated, as necessary. - Conversely, if an instruction is written in explict word-length notation (using the “
.w” extension to the mnemonic), its address will be always of word size, regardless of its actual value.
- If a load or store instructions is written in explicite byte-length notation (either using the “
- Otherwise, there’s a common convention to tread addresses like “
$0020” as word-sized operands (whereas “$20” would be a zeropage address). Generalizing on this for symbol definitions and expressions (where a word-length tainting acquired during parsing propagates to expression solving), we arrive at the following rules for automatic zeropage inference:- If an address is provided as a hex number of at least 4 digits, where the two leading digits are zeros, it will be considered of word-length.
(This applies to both “$00..” and “0x00..” notation.) - If a symbol is defined using such a notation or by an expression including such a notation, it, and any values derived from it, will be considered of word size.
- Similarly, the result of any expressions involving such a symbol or number will be considered to be of word-length, as well.
- If a symbol is part of an expression and its value is yet unknown (but will resolve in pass 2), the result of the respective expression will be considered to be of word-length. (Because it could be anything and we just don’t know, yet.)
- Unary byte-modifiers like “
<” or “>” remove any such word-length tainting from the value they are applied to. - Finally, if there is no word-length tainting, the size of the result of any expression will be considered, when it is actually used as an address operand. I.e., if it fits in a single byte, it will be a zeropage mode, otherwise “normal” absolut address modes will be used.
- If an address is provided as a hex number of at least 4 digits, where the two leading digits are zeros, it will be considered of word-length.
A final note on the “magic” address symbol “*”: you may provide a second parameter on any assignments to specify an optional fill byte (otherwise, any gaps between compiled areas of code will be filled by zeros).
While
* = $800 * = $810 .END
will result in no code generated (we’re just setting and resetting the program counter), while
* = $800 * = $810 0 .END
results in 16 zero bytes (from 0x0800 to 0x080F) compiled.
Using assignments to “*” and optional fill-byte values, we can achieve any kind of fills, reserving of space, alignments to page bounderies, etc, without any special pseudo-instructions.
Compatibility
In spite of all these new features, the assembler still supports a wide variety of syntax formats and notations, providing compatibilty to both old and new styles.
E.g., these two notations are equivalent and result in the same binary code:
;MOS notation
* = $C000
LDY *$20
LOOP LDA $0080,Y
ROL A
STA ($C0)Y
DEY
BNE LOOP
RTS
.END |
;modern style
.org 0xc000
ldy.b 0x20
loop: lda.w 0x80,y
rol
sta (0xc0),y
dey
bne loop
rts
.end |
There are no special requirements regarding white space, other than there MUST be some white space between an opcode and its operand and that there MUST NOT be any white space in an operand, address, or value expression. (Both requirements are pretty common.)
Illegal Opcodes
In order to activate support for illegal opcodes (this is default off in order to avoid conflicts with any 3-letter labels used in any legacy code) use the pragma “.OPT ILLEGALS”. This will activate the following opcodes (and their common synonyms, here provided in parentheses) — well, here’s a bit of green-bar… ;-)
| opc (synonyms) imp imm abs abX abY zpg zpX zpY inX inY |
| ALR (ASR) 4B |
| ANC 0B |
| ANC2 2B |
| ANE (XAA) 8B |
| ARR 6B |
| DCP (DCM) CF DF DB C7 D7 C3 D3 |
| ISC (ISB, INS) EF FF FB E7 F7 E3 F3 |
| LAS (LAR, LAE) BB |
| LAX (ATX) AB AF BF A7 B7 A3 B3 |
| LXA (LAX imm) AB |
| RLA 2F 3F 3B 27 37 23 33 |
| RRA 6F 7F 7B 67 77 63 73 |
| SAX (AXS, AAX) 8F 87 97 83 |
| SBX CB |
| SHA (AXA, AHX) 9F 93 |
| SHX 9E |
| SHY (SAY, SYA) 9C |
| SLO (ASO) 0F 1F 1B 07 17 03 13 |
| SRE (LSE) 4F 5F 5B 47 57 43 53 |
| TAS (SHS, XAS) 9B |
| USBC EB |
| NOP EA 80 0C 1C 04 14 |
| DOP (SKB) 80 04 14 |
| TOP (SKW) 0C 1C |
| JAM (HLT, KIL) 02 |
Interoperability
As we are eventually running out of highlights, there is still one left, namely some limited interoperability with the emulator: once you successfully assembled some code, a button “show in emulator” will show up below the code panel. Click this button to open the emulator (when not already opened previously) and set up the emulator in order to run this code. (Only the actual code will be inserted into memory, leaving the rest undesterbed — you may experiment on some pre-existing data —, and the CPU will be reset with PC pointing to the new start address.)
Disassembler (Updated, June 25, 2021)
The final piece in the Virtual 6502 suite is the disassembler.
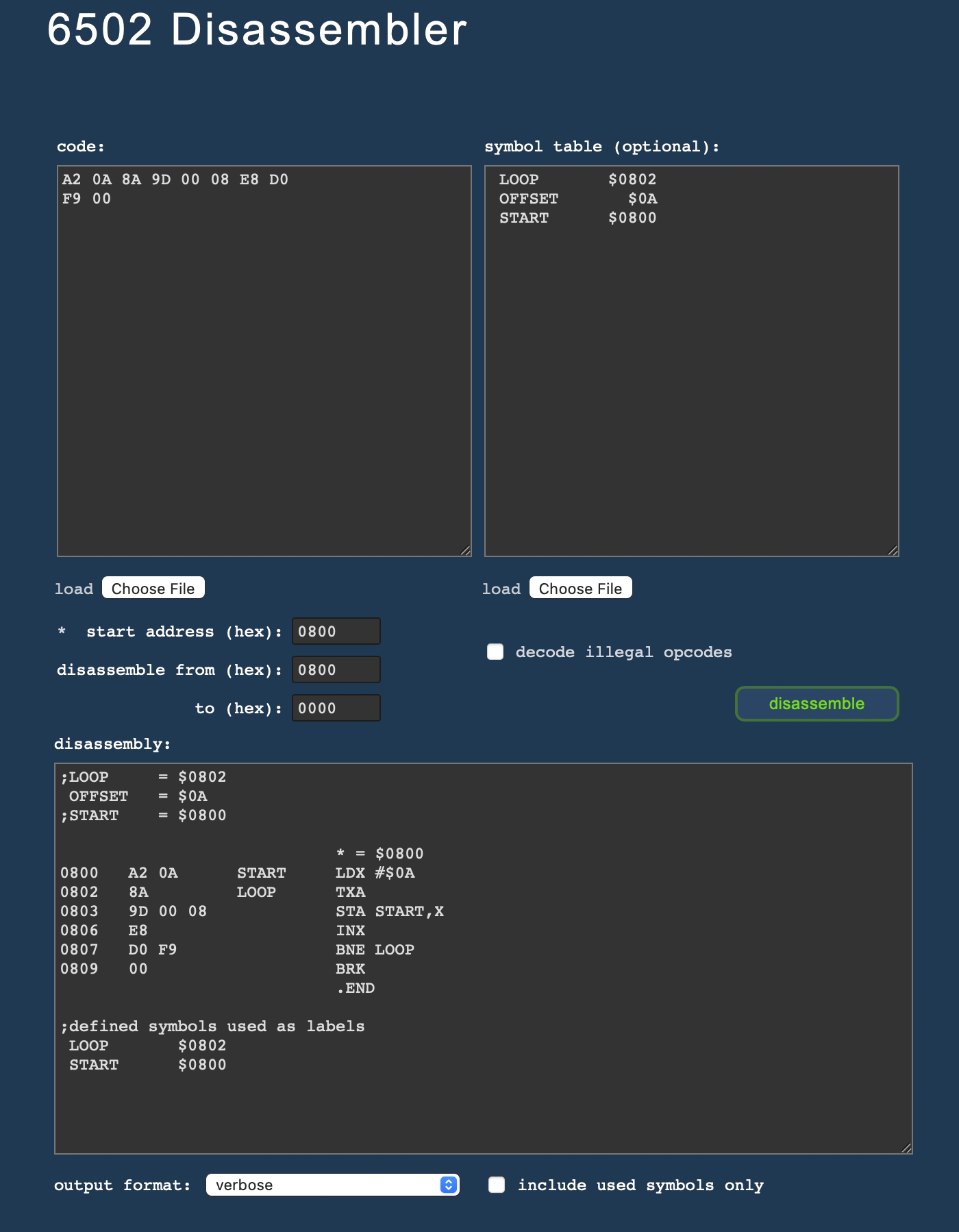
As all the other apps, it received support for illegal opcodes. As is the case with the assembler, this option is off by default — here, in order to facilitate an easy recognition of any data segments. (Usually, you want to get a broader overview first and then, maybe, refine the result.) But, if you want this feature, there’s a new checkbox in reach to activate the “illegal opcodes” option.
However, the real highlight is the newly adopted support for symbol tables. These may be again complex expressions, just as the ones used by the assembler. However, we are a bit more permissive on white space and also support normal parantheses (“(…)”) in addition to square brackets for grouping. And, of course, you may use symbols already defined in these expressions.
Symbol names may be separated from their value expressions by either a regular assignment (“=”), a colon (“,”), or just some white space (blanks). Meaning, you may reuse symbol definitions used by the assembler or even copy the symbol table as listed by the assembler. (The symbol table input supports drag & drop, just like the source panel, and has also a file-upload button of its own. So that you may save and reuse frequently used definitions as kind of an header file.)
To complete the circle, the disassembler lists the symbols in front of the disassembly with any symbols occuring as actual labels commented out, so that you may use the disassembly unchanged as an input to the assembler.
For this, there is an assembly-only view of the disassembly (without addresses or code literals), and there are even views without any labels and numeric values only, as well.
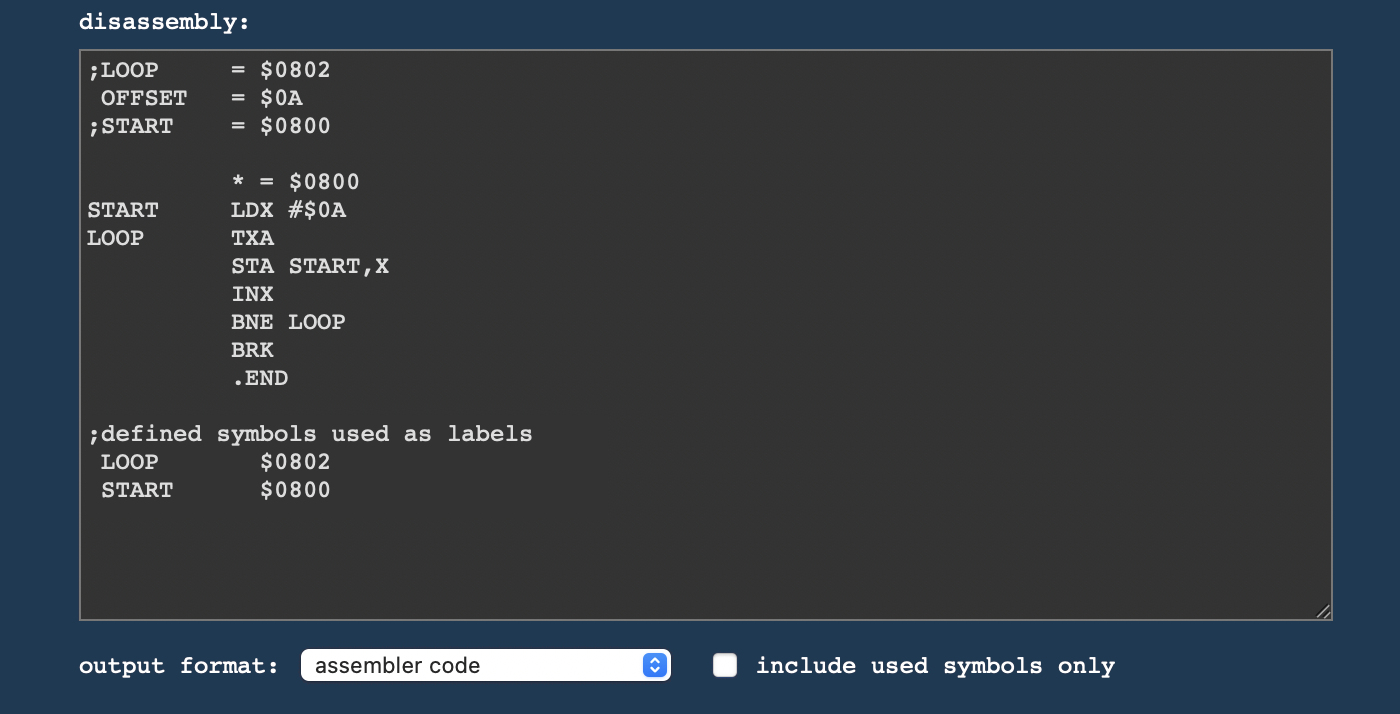
(Any unrecognized bytes will be automatically converted into “.BYTE” pseudo-instructions for these assemebler code views.)
Mind that using the “illegal opcodes” option an identical result on reassembly is not guaranteed, since there are multiple homonymous instructions (especially various “NOP” and “JAM” instructions.)
And this actuall all, folks. — Well, at least the essential stuff.
If you like this stuff or find it even useful, you may consider supporting my efforts by fueling me by a bit of coffee here:
Buy me a coffee :-)
Norbert Landsteiner,
Vienna, 2021-06-24